 In questo articolo presentiamo una descrizione dettagliata della nuova architettura CPU di AMD: Bulldozer. Entreremo nel dettaglio dell’architettura e dei vari componenti integrati nel chip. Al debutto oggi quattro nuovi modelli basati su questa architettura: FX-8150, FX-8120, FX-6100, FX-4100. Ne vedremo le caratteristiche dopo aver spiegato nel dettaglio le novità introdotte da AMD.
In questo articolo presentiamo una descrizione dettagliata della nuova architettura CPU di AMD: Bulldozer. Entreremo nel dettaglio dell’architettura e dei vari componenti integrati nel chip. Al debutto oggi quattro nuovi modelli basati su questa architettura: FX-8150, FX-8120, FX-6100, FX-4100. Ne vedremo le caratteristiche dopo aver spiegato nel dettaglio le novità introdotte da AMD.
Introduzione
Il progetto Bulldozer nasce nel 2006 come un’architettura ridisegnata da zero. La sua uscita era prevista nel 2009 su processo 45nm SOI ma, come è noto, questo progetto è stato cancellato.
Non è dato sapere se il progetto originale avesse una architettura simile a quella che andremo a presentare oggi: rumors vari indicavano la possibilità di una architettura molto veloce, con basso FO4 (ritardo normalizzato di uno stadio della pipeline) e un numero di stadi di pipeline elevati, dunque simile all’infausta architettura NetBurst, od anche una architettura simile, se non identica, a quella attuale di Bulldozer, o entrambe le ipotesi.
Quello che è noto è che il progetto ha mantenuto per tutto il tempo lo stesso nome: Bulldozer.
La versione finale di Bulldozer si configura come una mini rivoluzione nel campo della progettazione delle CPU. Dalla disamina dei brevetti AMD e dei lavori scientifici pubblicati sugli argomenti si deduce che molto di questo lavoro è confluito nello sviluppo di questa architettura.
Gli innumerevoli ritardi hanno fatto crescere le aspettative degli utenti e l’ultimo slittamento, da luglio ad ottobre, ha fatto sorgere ulteriori interrogativi sul motivo di una tale scelta. AMD dal canto suo, aveva annunciato che quest’ultimo posticipo era stata una scelta esclusivamente di marketing, senza alcuna implicazione di natura tecnologica.
Oggi le CPU Bulldozer vengono presentate da AMD come le prime CPU desktop ad 8 core, e come le CPU più veloci sul mercato, grazie ai record di overclock ottenuti in termini di frequenze raggiunte, ben 8429 MHz utilizzando sistemi di raffreddamento estremi.
Vedremo ora in dettaglio l’architettura di Bulldozer, per cercare di apprezzare meglio anche queste affermazioni.
Architettura di sistema
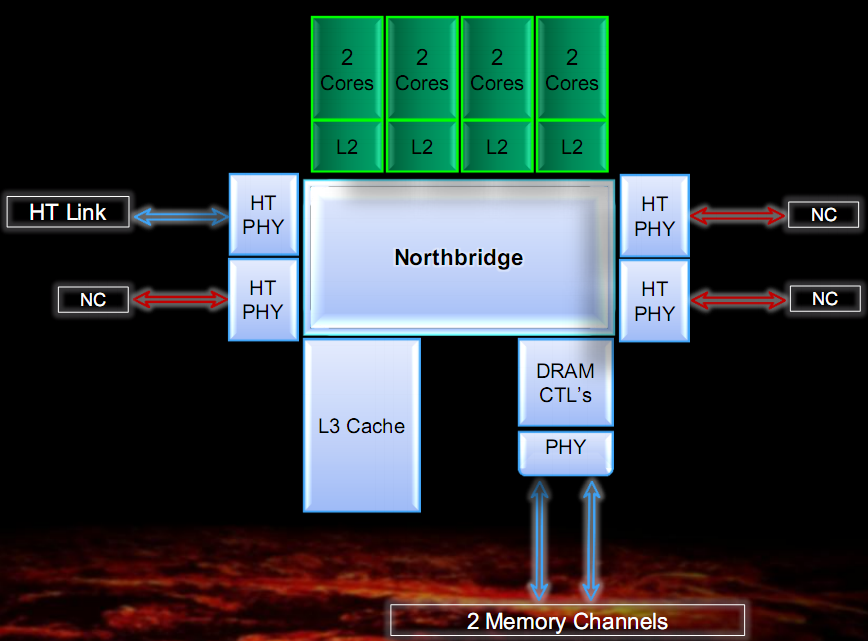
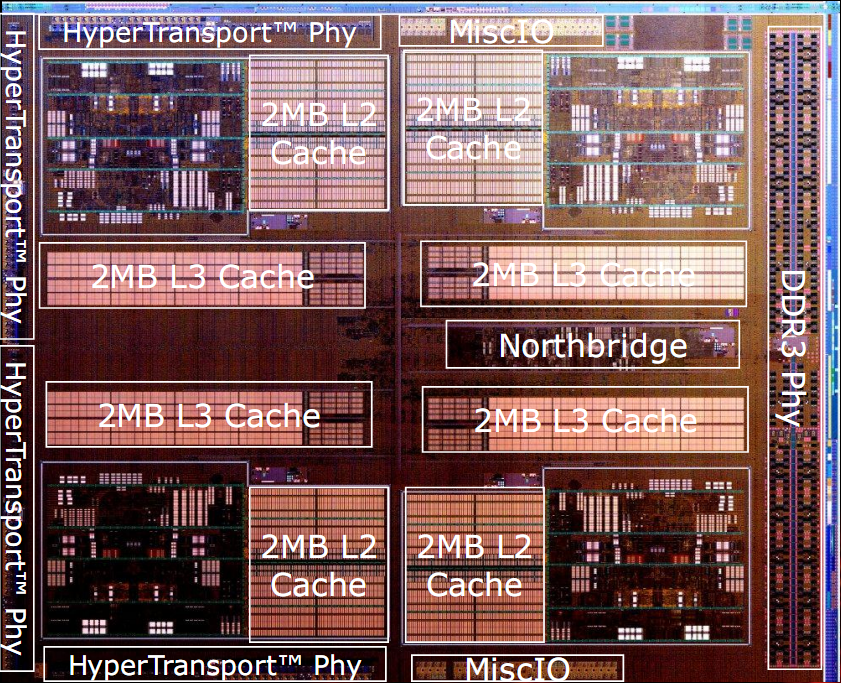

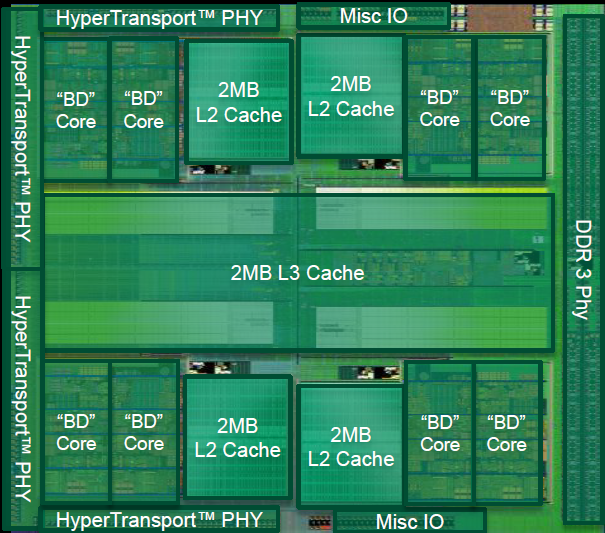
In figura sono riportati lo schema a blocchi semplificato e due foto del die di Bulldozer, con in evidenza i vari componenti dell’architettura.
La prima cosa da notare è che l’unità minima di elaborazione è il cosiddetto modulo, che implementa due core di classe Bulldozer.
L’architettura del chip comprende quattro moduli, ognuno composto da due core e 2MB di cache L2 condivisa, un North Bridge che gestisce l’interconnessione tra tutti gli elementi del chip, una cache L3 condivisa da 8MB, un controller di memoria DDR3 dual channel e quattro controller HyperTransport, di cui uno solo attivo nelle CPU di classe desktop.
Lo scopo ultimo dei progettisti AMD era di massimizzare il rapporto performance per watt, tenendo conto anche della superficie occupata. Questo è stato ottenuto in vari modi. Dall’analisi della letteratura è emerso che esiste una complessità ottimale della pipeline di un processore per avere il miglior rapporto performance per watt.
Pipeline semplici e con un numero elevato di stadi consentono di avere clock alti, ma IPC (istruzioni per clock) bassi. Il consumo esplode all’aumentare del clock e quindi non si può aumentare troppo tale parametro, arrivando a un limite invalicabile sulle prestazioni.
Pipeline complesse e con pochi stadi sono più lente, ma hanno IPC elevati, bilanciando il clock più basso. Avendo un numero elevato di transistor, occupano più area del chip e consumano una parte superiore di energia in leakage (correnti di dispersione), dovuto al numero elevato di transistor. Questo si traduce anche in un’ulteriore limitazione per il clock massimo ottenibile.
La condizione ottimale è a metà strada tra questi due estremi ed è stato stabilito da vari studi teorici in letteratura. Un indice della complessità di una pipeline è il FO4, che indica quanto è il ritardo normalizzato di uno stadio di pipeline. Maggiore è questo numero, più complesso (e lento) è lo stadio della pipeline, e auspicabilmente meno stadi di pipeline sono necessari per implementare una data architettura.
E’ stato dimostrato che un FO4 di 17 è l’ottimo per una CPU realizzata sui moderni processi produttivi. Tale valore è quello utilizzato per le pipeline di Bulldozer. A titolo di confronto, il FO4 di un K10 è circa 22, quello di un Sandy Bridge circa 24 e quello di un Pentium 4, circa 13. Per il discorso fatto prima, è chiaro che K10 e Sandy Bridge sono architetture con pipeline complessa e clock basso mentre il Pentium 4 è una architettura con pipeline semplice e clock alto.
Determinata la complessità ottimale della pipeline ora il problema è implementare la Cpu con il minimo numero di transistor.
Una delle cose che è stata fatta è la condivisione di tutte le unità sottoutilizzate. Questo è il motivo della nascita del modulo.
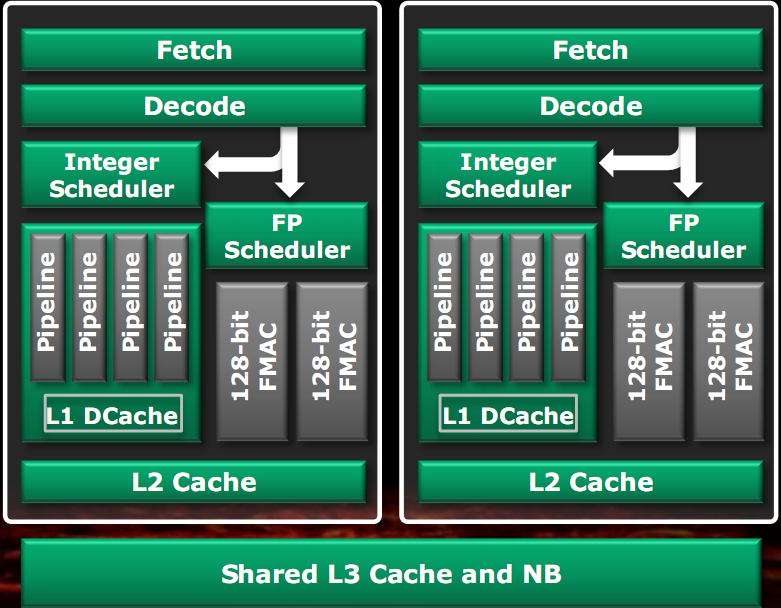
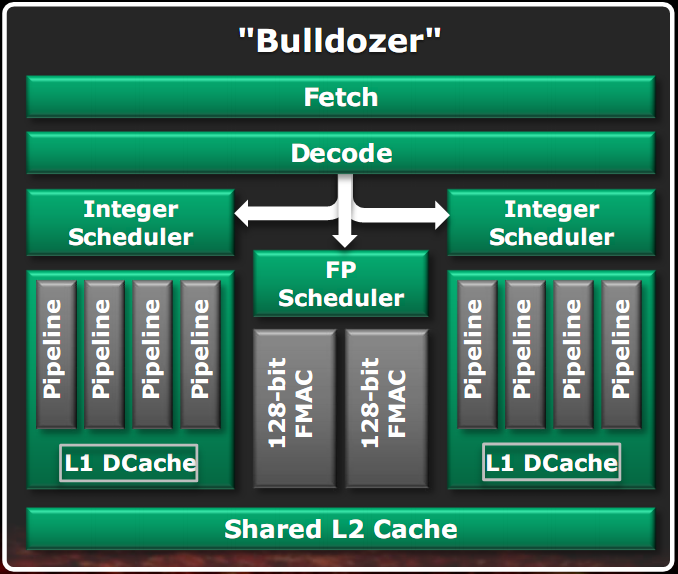
Nella figura di sinistra è visibile la classica implementazione di una CPU dual core, con la duplicazione della maggior parte delle componenti.
Nella figura di destra è visibile uno schema a blocchi di un modulo Bulldozer.
Le unità che non sono utilizzate in pieno per la maggior parte del tempo sono state condivise tra i due core, potendo così anche renderle più potenti rispetto al caso di unità separate, poiché ora il budget di transistor si divide tra due core e quindi è possibile utilizzarne di più per una singola unità.
Come visibile in figura, le unità condivise sono l’unità di fetch, l’unità di decodifica, l’unità Floating Point e la cache L2. Le cache L1 dati e le unità intere sono rimaste separate poiché si è stabilito che esse sono le unità più utilizzate di un core. Questo approccio consente di eseguire due thread con una velocità media pari all’80% rispetto al caso di core separati, in un’area di solo il 12% in più rispetto a quella di un singolo core (escludendo dal computo la cache L3, il North bridge e il controller RAM).
Abbassare il numero di transistor, abbassa il leakage e quindi consente clock più alti a parità di TDP. Ma per avere clock ancora più alti è necessario avere un risparmio energetico molto efficace.
Le strategie implementate in Bulldozer sono le seguenti: clock gating estensivo delle reti logiche su tutto il die, ossia spegnimento del clock per le unità non utilizzate in un dato istante, power gating estensivo dei circuiti logici, ossia spegnimento anche dell’alimentazione elettrica per le unità non utilizzate in un dato istante, implementazione dello stato C6 di spegnimento dei moduli o dell’intero package, tramite anelli di transistor attorno alle unità, P-state di risparmio energetico o di turbo core, per avere in ogni istante il consumo ottimale in funzione del carico, caratteristica permessa dal modulo APM (advanced power management) che misura istante per istante il consumo del chip e determina il P-state ottimale, risparmio energetico dei moduli RAM ed infine stato di risparmio energetico C1E, in cui un core in idle consuma il meno possibile senza essere spento completamente.
Ultima caratteristica implementata in Bulldozer è il Turbo Core.

Il Turbo core si serve della unità APM per determinare quanto tempo la CPU può stare nel massimo stato di turbo possibile senza oltrepassare il consumo massimo stabilito. Quando sono utilizzati tutti i core, c’è quasi sempre qualche unità non utilizzata nel chip. L’unità APM calcola il budget di TDP e l’unità del turbo core, tramite un algoritmo di dithering, calcola quanto tempo la CPU può stare in stato di turbo senza oltrepassare il TDP. Se poi sono utilizzati la metà o meno dei core, lo stato di turbo utilizzabile prevede un clock ancor più elevato.
Veniamo ora a un elenco delle caratteristiche principali delle varie unità di un modulo Bulldozer.
Unità di Fetch e Decodifica
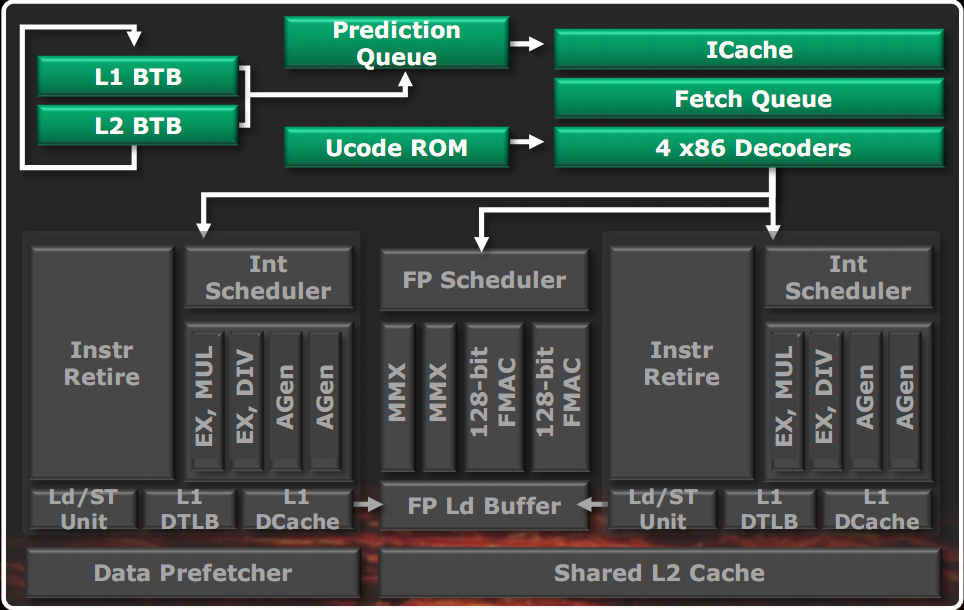
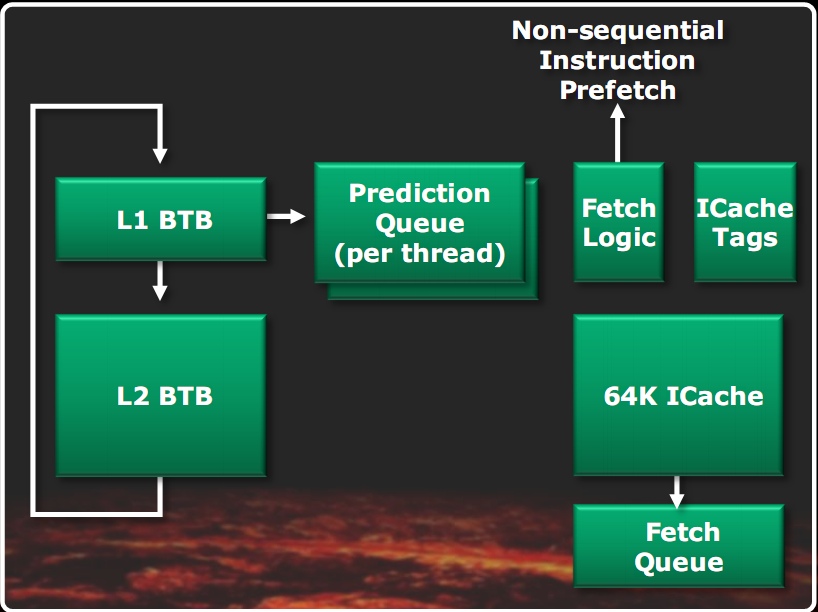
Nella figura di sinistra vediamo evidenziato il front end di un modulo Bulldozer. In quella di destra è riportato più in dettaglio lo schema del predittore di salto.
Rispetto alle architetture classiche, vediamo l’unità di predizione salti disaccoppiata dall’unità di fetch vera e propria: questo consente di effettuare le predizioni dei salti in parallelo e indipendentemente dal fetch delle istruzioni. Il prefetch è guidato dalla predizione dei salti, per trovare in cache le istruzioni necessarie il più presto possibile. La cache istruzioni è di 64KB a due vie. Il fetch delle istruzioni avviene 32 byte alla volta. I TLB istruzioni sono a due livelli, con un primo livello di 72 elementi fully associative, condiviso tra tutte le misure di pagina e un secondo livello di 512 elementi a 4 vie, con le sole pagine da 4KB. L’unità di decodifica è anche capace di effettuare il branch fusion. I decoder sono 4 e possono generare 4 macro istruzioni per clock, alternativamente per i due thread.
Il predittore dei salti è doppio e lavora indipendentemente per i due thread. Le richieste di prefetch sono fatte in parallelo alla cache L2 e alla memoria, qualora manchino in cache L1. Il predittore, oltre a essere diviso per thread, è anche diviso in due livelli. Il primo livello è più veloce, ma meno preciso, basandosi anche su una cache L1 BTB (Branch Target Buffer, ossia una cache che memorizza gli indirizzi IP dei salti eseguiti in passato, che il predittore restituisce come predizione, qualora il salto sia predetto come preso) più piccola (di 512 elementi). La sua predizione è depositata nella coda opportuna ed è avviata in parallelo la predizione di secondo livello, che si avvale, tra l’altro di una cache L2 BTB molto più grande (5120 elementi). Quando la predizione di secondo livello è pronta, se il risultato della predizione di primo livello non è stato ancora utilizzato, esso viene sovrascritto da quella di secondo livello, presumibilmente più preciso. Ciò permette di unire i vantaggi di un predittore veloce, con quello di uno accurato. La predizione dei ritorni a procedura è effettuato da una unità separata.
Unità intera
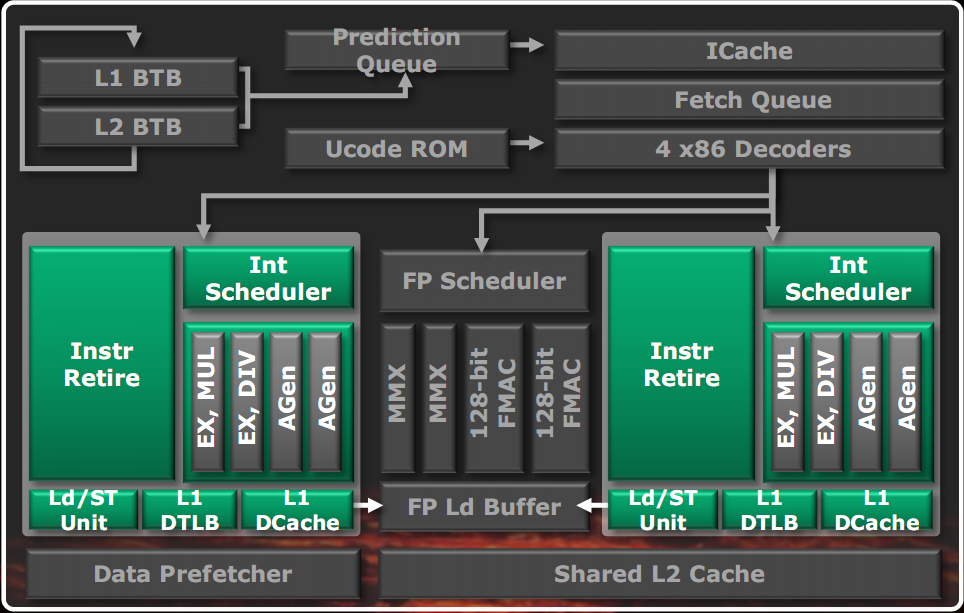
In figura è visibile un diagramma semplificato delle due pipeline intere contenute in un modulo Bulldozer.
Ognuno dei due core è dotato di uno scheduler unificato delle istruzioni, capace di eseguire le istruzioni non appena i dati e le unità esecutive necessarie sono pronte. Le unità di esecuzione sono 4, di cui due capaci di eseguire istruzioni di calcolo indirizzo e istruzioni aritmetico logiche semplici (AGen), una in grado di eseguire istruzioni aritmetiche complesse, nonché moltiplicazioni (Ex, MUL) ed una in grado di eseguire istruzioni aritmetiche complesse, nonché divisioni (Ex, DIV). Ogni unità è dotata di una cache dati L1 da 16KB, con politica di scrittura write through e prevalentemente esclusiva rispetto alla cache L2, di una TLB dati da 32 pagine fully associative e una unità di load/store completamente out of order, capace di eseguire due letture a 128 bit e una scrittura a 128 bit per ciclo, con una coda di 40 posizioni in lettura e 24 in scrittura.
Unità Floating Point
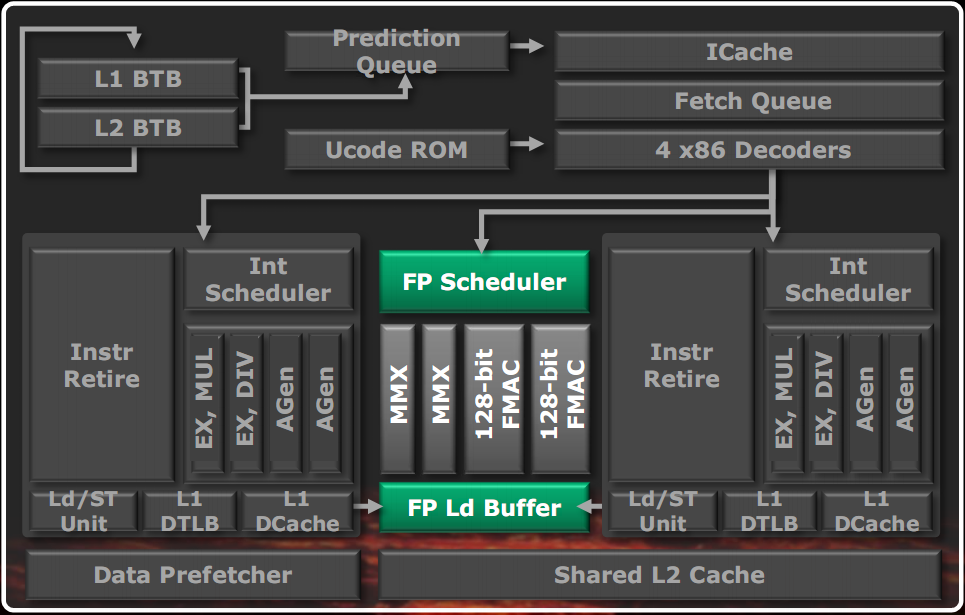
In figura è visibile un diagramma semplificato dell’unità floating point (FP) contenuta in un modulo Bulldozer. Essa è organizzata come un coprocessore esterno, che riceve le istruzioni da eseguire dall’esterno e riporta i risultati indietro ai core richiedenti. Il collegamento tra unità FP e core interi è bidirezionale: riceve istruzioni e dati dai core interi, riporta un segnale di completamento indietro (il ritiro delle istruzioni è comunque gestito dai core interi), è collegato con due bus a 64 bit ai core interi per l’esecuzione di istruzioni di conversione da interi a numeri FP e viceversa ed è collegato alle unità di lettura e scrittura dei due core interi per l’esecuzione delle operazioni di memoria.
E’ composta da uno scheduler unificato, che può ricevere fino a 4 istruzioni per ciclo di clock a cicli alterni dalle due unità intere e mandare in esecuzione fino a 4 istruzioni per ciclo di clock, anche miscelando quelle di entrambi i thread, a 80/128 bit. Lo scheduler è completamente guidato dai dati: non appena i dati e l’unità di esecuzione necessaria sono liberi, l’istruzione è mandata in esecuzione, facendo attenzione ad essere equo tra i due thread.
Le unità di esecuzione sono 4 e sono in grado di eseguire 2 operazioni FMAC (Fused Multiply Accumulate, ossia una moltiplicazione e un accumulo fusi assieme, dunque un calcolo del tipo d=a+b*c) FP e 2 operazioni IMAC (Integer Fused Multiply Accumulate, come la FMAC ma su numeri interi) per ciclo. Le operazioni x87 sono gestite dalle FMAC. Le divisioni e le radici quadrate sono gestite sempre dalle FMAC. Alcune operazioni particolari sono gestite dalle IMAC, come quelle di permutazione, quelle di memoria da una delle due pipeline IMAC e i movimenti tra registri sono per la maggior parte eseguiti al volo senza occupare unità di esecuzione. Grazie a un brevetto depositato da AMD, le unità FMAC e IMAC sono in grado di eseguire anche addizioni o moltiplicazioni semplici con lo stesso circuito, senza duplicazioni inutili. Le unità sono a 128 bit e possono essere unite insieme per effettuare operazioni a 256 bit.
Cache L2 e sistema memoria
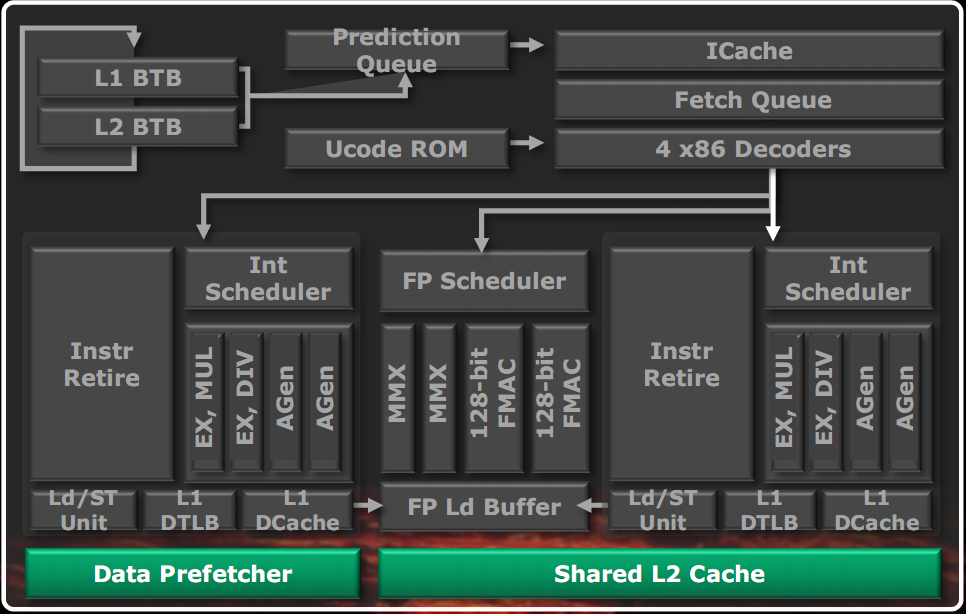
La cache L2 è pari a 2MB organizzata a 16 vie. La TLB di secondo livello è di 1024 pagine a 8 vie e serve sia le cache dati che quella istruzioni. I prefetcher sono multipli e la L2 può avere fino a 23 transazioni in sospeso verso la memoria.
La cache L3 è anch’essa di 8MB organizzata in 4 banchi da 2MB ed è condivisa tra i 4 moduli. E’ una victim cache, ossia contiene i dati che devono essere tolti dalle cache L2 dei vari moduli, per fare posto ai nuovi dati. Essa lavora alla stessa frequenza del North Bridge che gestisce anche quattro controller HyperTransport e un controller memoria DDR3 a doppio canale che supporta fino a 4 moduli di memoria e memorie fino a 1866 MHz.
Istruzioni supportate
Le istruzioni supportate da Bulldozer sono le SSE fino alle 4.1 e 4.2 incluse, le AVX con registri a 256 bit, le istruzioni AES per l’accelerazione della crittografia e istruzioni FMA a 4 operandi non distruttivi (set di istruzioni XOP).
Cpu al debutto
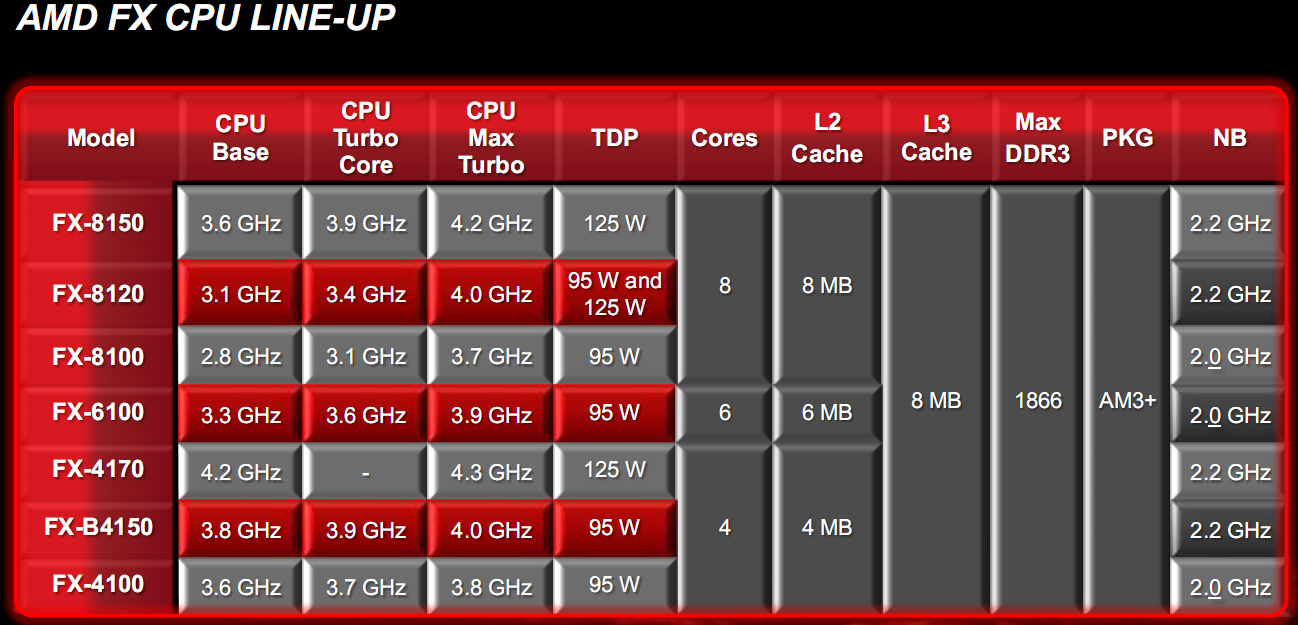
In figura è visibile il prospetto delle varie CPU Bulldozer previste a partire dal 12 ottobre 2011. Come è possibile notare, sono previsti 4 modelli della serie FX 8xxx a 125W e 95W a 8 core (i modelli FX 8150, FX 8120 e FX 8100), un modello a 6 core della serie FX 6xxx (FX 6100) e tre modelli a 4 core della serie FX 4xxx (i modelli FX 4170, FX B4150 e FX 4100), con il record di frequenza per le CPU desktop dato dalla CPU FX 4170, con 4.2GHz, che sarà introdotto in seguito.

In questa figura è visibile la lista delle CPU disponibili al lancio a partire dal 12 ottobre 2011, unitamente ai prezzi di vendita suggeriti. Come possiamo notare abbiamo due CPU della serie FX 8xxx a 125W (FX 8150 e FX 8120, la cui versione a 95W sarà introdotta in seguito) ad un prezzo retail suggerito di 239/249€ e 199/209€, rispettivamente, e due modelli a 4 e 6 core da 95W (FX 4100 e FX 6100), con un prezzo suggerito di 109/119€ e 149/159€, rispettivamente. Purtroppo i prezzi in euro non sono altrettanto interessanti quanto quelli in dollari, con la CPU top di gamma AMD che si posiziona ad un prezzo di poco inferiore alla CPU Intel Core i7-2600k, che si aggira attualmente attorno alle 260/270€. Dal punto di vista delle funzionalità la CPU, FX-8120 è comunque identica all’FX-8150, fatta eccezione per una frequenza di clock inferiore. Occore quindi valutare le potenzialità in overclock di queste CPU per capire le reali potenzialità delle CPU Bulldozer.
Nei prossimi giorni pubblicheremo una analisi dettagliata delle prestazioni, che consentiranno di scegliere la CPU più adatta alle proprie esigenze.
Bench preliminari
La linea di processori AMD FX si distingue, tra l’altro, per le frequenze operative, per il numero di core e per il fatto di avere moltiplicatori sbloccati:

I bench preliminari che riportiamo di seguito, sono realizzati dalla stessa AMD e riportano ottime prestazioni con i giochi e prestazioni comparabili ai processori INTEL di pari prezzo negli altri benchmark.
I test si riferiscono a confronti tra CPU AMD FX-8150 e Phenom X6 e CPU INTEL di volta in volta specificate. Per uniformità si è scelto di avere 8GB di memorie DDR3 1333 (anche se questo penalizza un po’ le CPU AMD FX 8150, poiché esse supportano memorie fino a 1866 MHz) e Windows 7 a 64 bit.
Iniziamo con un confronto in situazioni di risoluzioni estreme, con configurazione Eyefinity e GPU in configurazione crossfire di HD6970, rispetto a un Core i5 2500K:
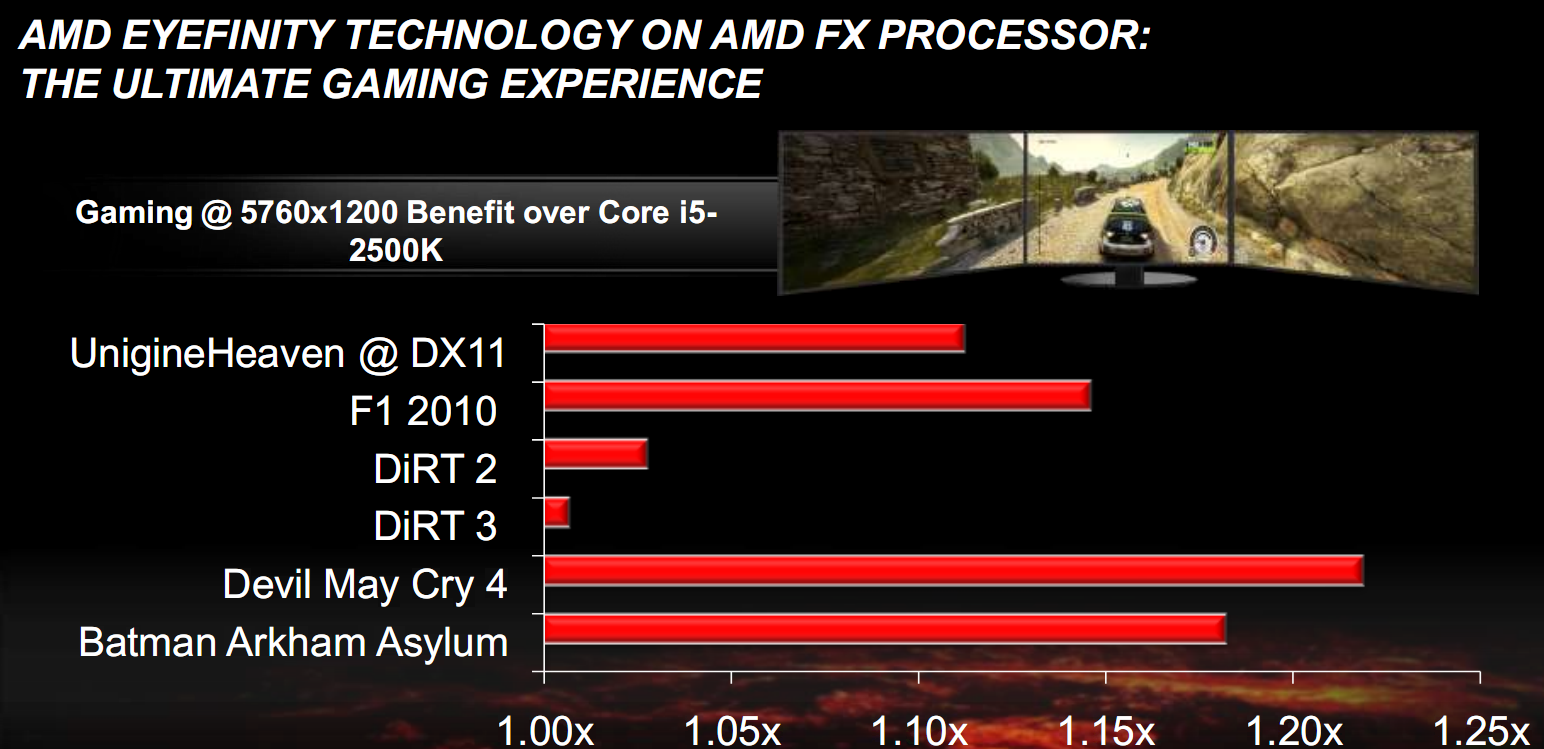
Come si può notare, i vantaggi sono evidenti e vanno da un minimo di 1% a un massimo del 22%.
Il test successivo riguardia Battlefield 3, confrontando le CPU AMD FX-8150, Phenom X6 e INTEL 2500K, con singola HD 6950.
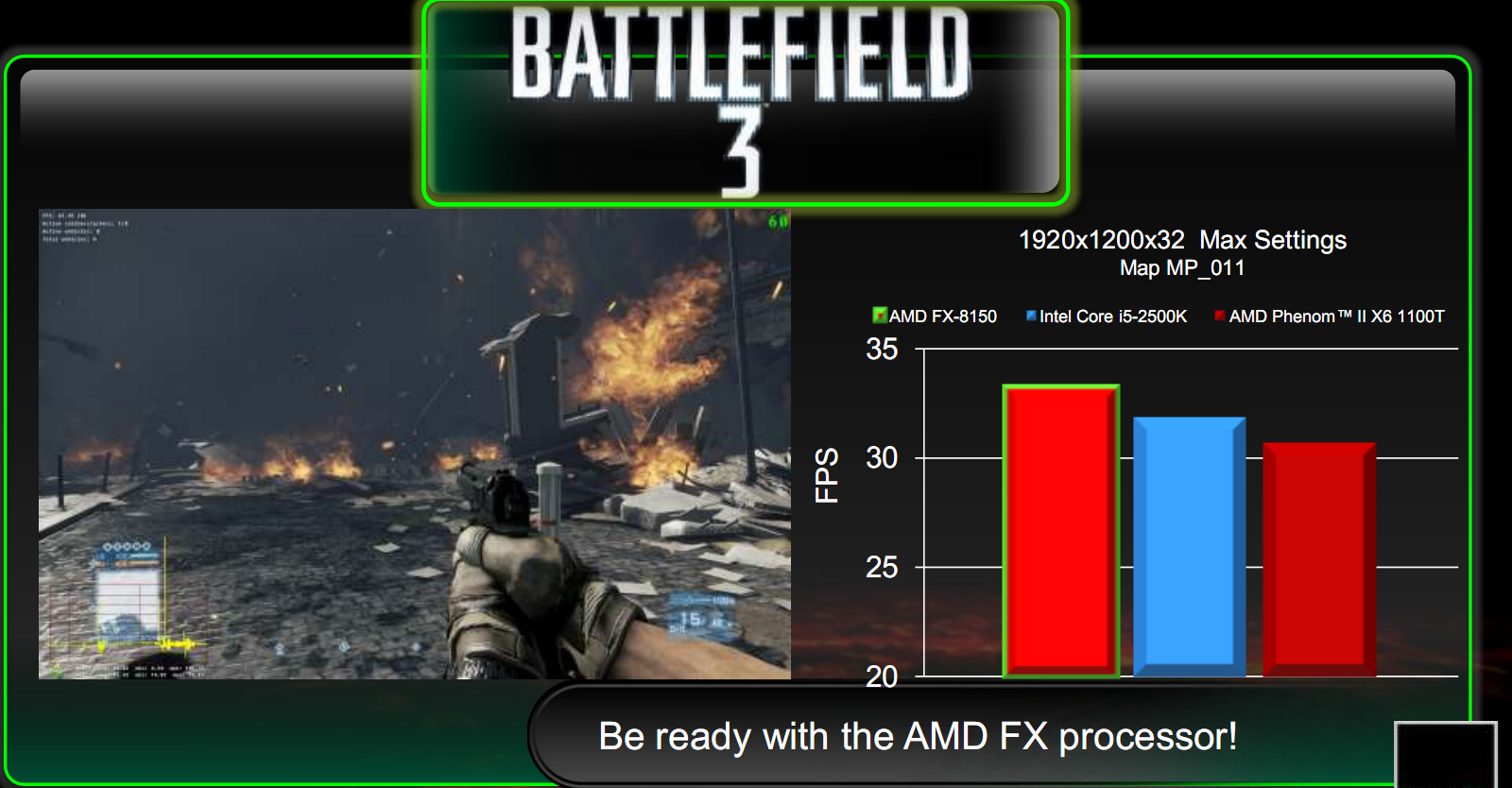
Il miglioramento delle CPU AMD da una generazione all’altra è di qualche FPS, sufficiente comunque a sopravanzare anche la soluzione Intel.
L’ultimo test gaming mostra un caso estremo: l’uso della CPU top di gamma INTEL Core i7 980x non è economicamente conveniente. Per giocare alla maggior parte dei giochi con prestazioni allineate o superiori (con due eccezioni), basta una CPU AMD FX 8150, risparmiando, inoltre, 800 dollari:
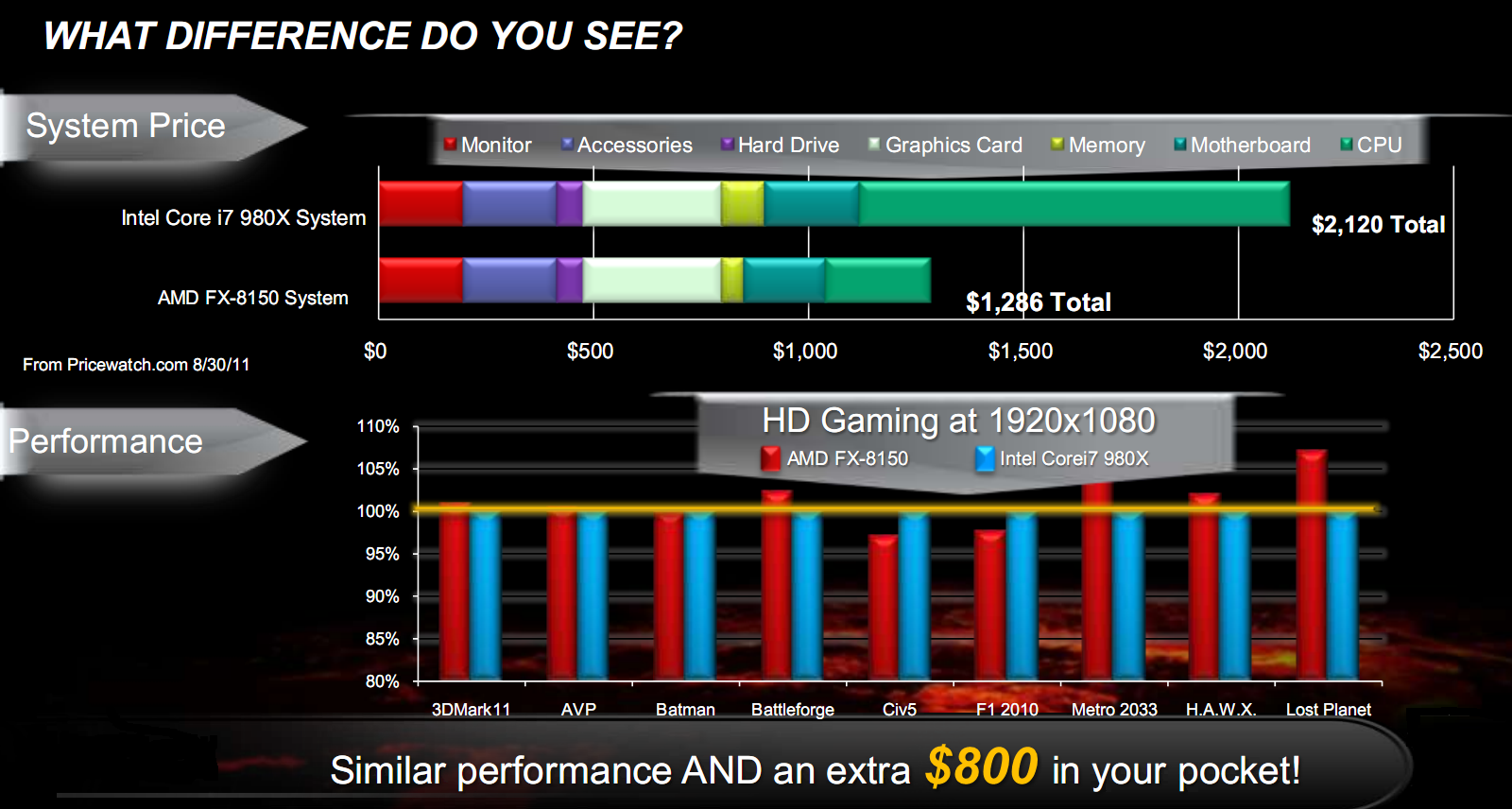
Manca purtroppo in questo caso il confronto con Sandy Bridge, diretto competitor di Bulldozer.
Venendo alle applicazioni multithreaded general purpose, l’FX 8150 è sempre superiore al 2500K (rispetto a cui è stato normalizzato il grafico) e generalmente allineato al 2600K, come visibile nel seguente grafico:
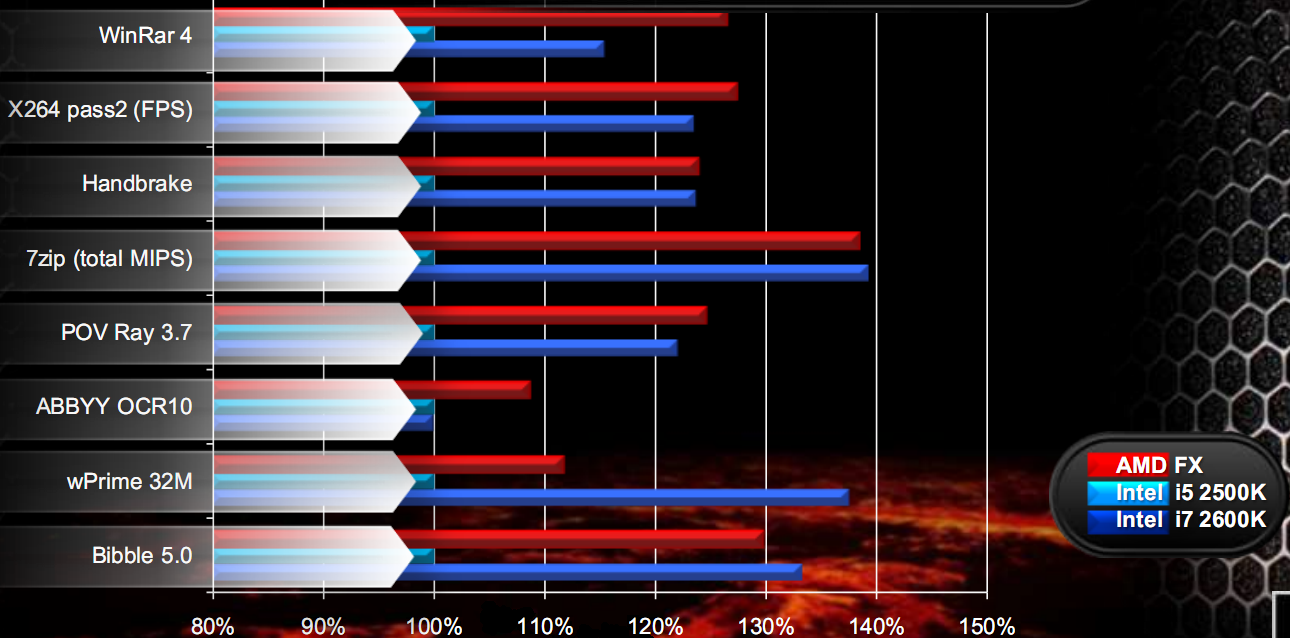
Tale slide risulta curiosamente diversa da quanto apparso alcuni giorni fa da alcune indiscrezioni, con i valori dell’AMD FX e del 2600K esattamente invertiti. Anche da questi test appare comunque evidente che gli 8 core Bulldozer non hanno prestazioni paragonabili a quelle di 8 core tradizionali, ma mostrano prestazioni generalmente paragonabili ad un quad core Intel con Hyper Threading.
Infine le prestazioni dell’FX 8150 in Cinebench 11.5 a 64 bit a default (3.6GHz) e con un overclock a 4.8GHz:

Tale risultato indica una buona scalabilità in frequenza, data da un incremento delle prestazioni del 31% a fronte di un incremento di clock del 33%, ma le prestazioni effettive potrebbero essere superiori utilizzando memorie a 1866 MHz anche a default ed infine si potrebbero ottenere maggiori prestazioni in overclock, incrementando anche la frequenza del North Bridge e delle RAM. Il risultato in termini assoluti non è però molto incoraggiante per una CPU definita ad 8 core.
Conclusioni e considerazioni
AMD torna con una nuova architettura ottimizzata per avere un miglior rapporto prestazioni, consumo e area, da cui deriva il costo di produzione. Ogni singolo elemento è stato scelto per avere il miglior compromesso. Diminuire il consumo consente di salire più di clock e consente di avere frequenze di turbo più elevate.
L’approccio di AMD usato per la condivisione delle risorse è chiamato Clustered Multi Thread (CMT). Contrariamente all’SMT di Intel, questo approccio non sacrifica eccessivamente le prestazioni in multi thread, quando due thread si contendono le risorse del modulo, poiché solo le unità realmente sottoutilizzate sono state condivise ed in più potenziate, poiché prendevano il posto di due unità.
AMD è finalmente al passo con i set di istruzioni Intel ed anzi implementa un suo set di istruzioni, lo XOP e le FMA4, che implementano il FMA a 4 vie (Fused Multiply Accumulate a 4 vie, ossia il calcolo della formula d=a+b*c, contrariamente al FMA 3 che calcola la formula a=a+b*c, distruggendo uno dei registri e richiedendone il salvataggio, qualora servisse il suo contenuto), che consente di ottenere grandi vantaggi in codice ottimizzato:
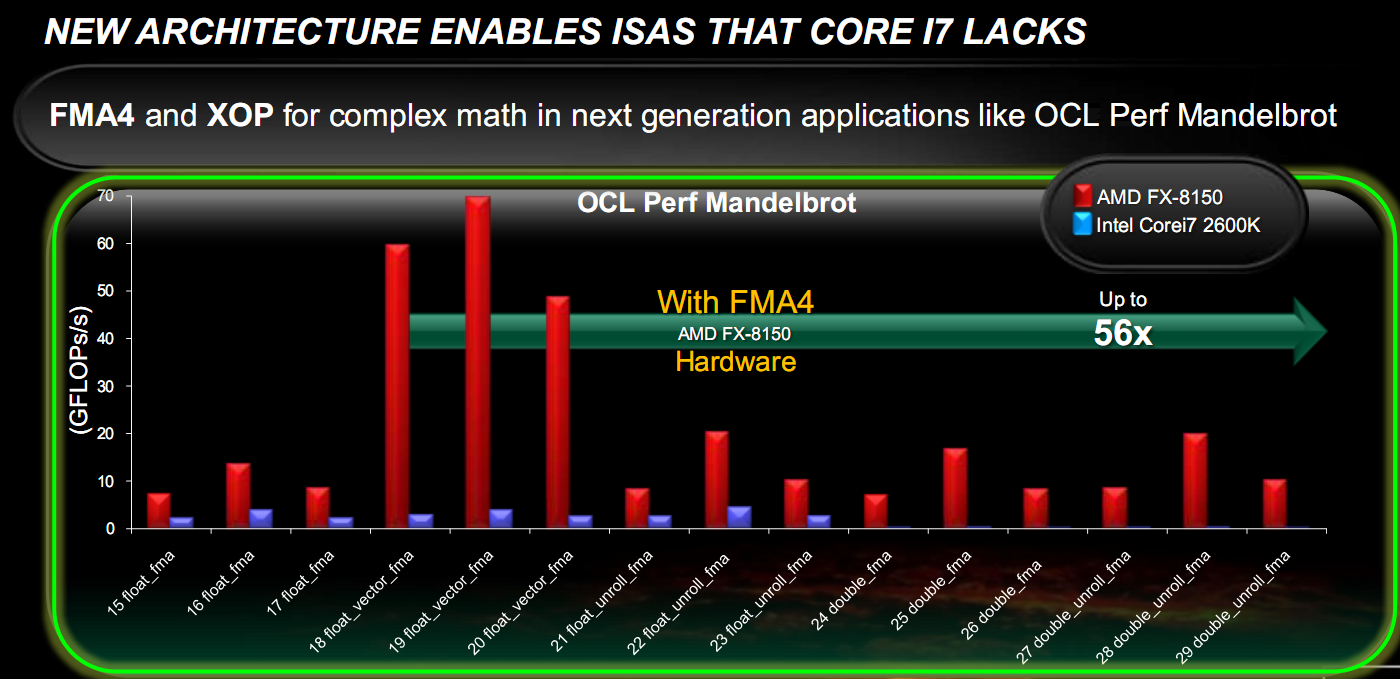
Infine il turbo core da vantaggi tangibili sulle prestazioni, cercando di sfruttare il potenziale di TDP inespresso dai vari software:

Il die Bulldozer in 315 millimetri quadrati racchiude 8 core per un totale di 2 miliardi di transistor, in grado di operare ad una frequenza di oltre 4 GHz rimanendo in un TDP di 125W. Questo è un risultato sicuramente di ottimo livello se consideriamo le passate architetture sia di Intel che di AMD.
AMD ha prodotto la prima CPU x86 a 8 core come lei stessa la definisce, anche se in effetti non ha le prestazioni che ci si aspetterebbe da un otto core reale in quanto la condivisione di parti di core ha comunque i suoi svantaggi. Dal punto di vista delle prestazioni, esse sono circa allineate a quelle di una cpu Intel dotata di 4 core e capace di gestire 8 thread. Ci preme dire ciò soprattutto per gli utenti più inesperti che potrebbero erroneamente fare la banale associazione "CPU con più core = CPU più potente".
Con questa cpu, AMD, vanta anche il nuovo record di frequenza in overclock estremo, pari a 8429MHz sotto elio liquido. Questi due primati sono di buon auspicio per la riuscita della CPU, confermate dai test preliminari effettuati da AMD. Ciò tuttavia non basta di certo a definire l'FX-8150 la CPU più veloce sul mercato, almeno non in termini assoluti.
Nei prossimi giorni pubblicheremo una approfondita analisi prestazionale di questa nuova architettura di AMD, con test estensivi effettuati in redazione, nonché una analisi più approfondita della architettura. Restate sintonizzati!
Marco Comerci