 In questo articolo presentiamo una descrizione dettagliata della nuova APU di AMD, nome in codice Llano. Entreremo nel dettaglio dell’architettura di sistema e dei vari componenti integrati nel chip. Effettueremo inoltre una comparazione con la precedente architettura, confrontando un A8-3850 con un Phenom II x4 840 e con un Phenom II 945.
In questo articolo presentiamo una descrizione dettagliata della nuova APU di AMD, nome in codice Llano. Entreremo nel dettaglio dell’architettura di sistema e dei vari componenti integrati nel chip. Effettueremo inoltre una comparazione con la precedente architettura, confrontando un A8-3850 con un Phenom II x4 840 e con un Phenom II 945.
Introduzione
La piattaforma Lynx è la piattaforma designata da AMD per il mercato desktop mainstream.
Il target di riferimento sono i desktop a basso consumo, come gli HTPC, i desktop All-in One e i sistemi desktop dedicati all’utilizzo office, navigazione e al gaming occasionale.
Il componente fondamentale è la APU Llano.
Dopo avervi mostrato le prestazioni e le feature della piattaforma Lynx e in particolare della CPU A8-3850 (ENGLISH VERSION), nelle seguenti pagine effettueremo un’analisi approfondita dell’architettura e dei componenti della APU Llano, a partire dai core della CPU che la compongono, includendo una comparativa delle prestazioni rispetto alla precedente architettura Stars, ossia Propus e Deneb, concludendo con una analisi di GPU integrata e Northbridge.

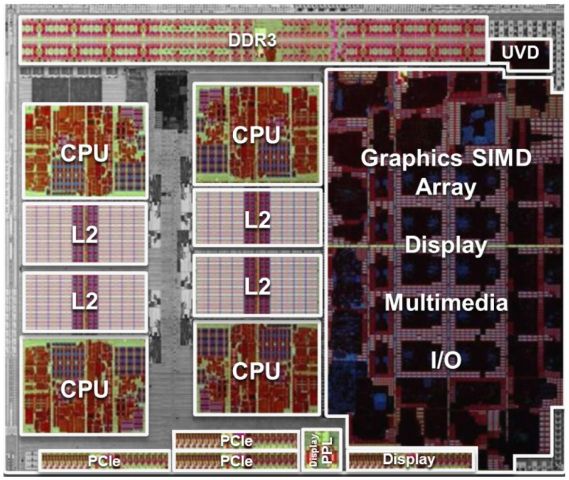
Nella prima figura è visibile un diagramma a blocchi semplificato del chip Llano. Nella seconda figura è visibile una foto del die Llano.
Il cuore della APU sono una serie di core CPU, ognuno dotato di proprie cache L1 e L2.
Elemento altrettanto importante è la GPU, di classe DirectX11, con annessa unità UVD di terza generazione.
Per i collegamenti esterni abbiamo un controller della memoria (MC) capace di supportare due canali DDR3 da 1866 trasferimenti al secondo, da 64 bit ognuno, e il modulo GIO, che include il bus PCI Express 2.0 a 24 linee per il collegamento sia di una scheda video aggiuntiva o di display aggiuntivi, sia per l’implementazione della Unified Media Interface per il collegamento al Fusion Controller Hub (FCH), sia per l’implementazione di 4 link PCI Express per non appesantire l’FCH, ed infine i collegamenti video, HDMI, Display Port e DVI.
Il centro di smistamento di tutti i dati è il north bridge (NB), che si occupa di instradare il traffico tra tutti i componenti menzionati in precedenza.
Ciliegina sulla torta è la tecnologia TurboCore 2.0, che effettua un overclock dinamico della CPU (e in future architetture anche della GPU) a seconda del carico di lavoro istantaneo di ognuno degli elementi.
CPU
L’architettura del core Llano riprende e migliora quella dei core “Stars”, apportando alcune migliorie visibili fin dallo schema a blocchi.
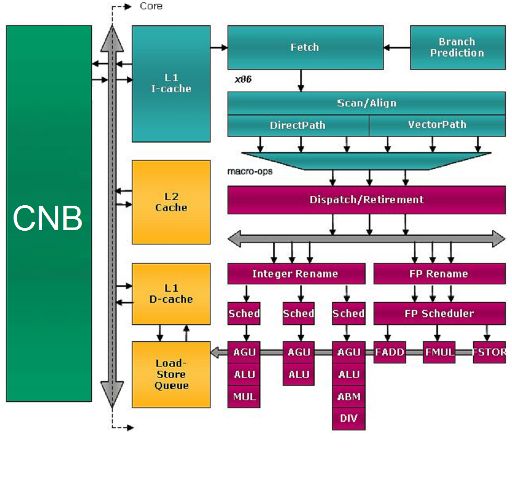
Il blocco di colore verde, contiene il North Bridge, il controller per l’I/O del Chip e il controller RAM ed è indicato in figura con la dicitura CNB. Sarà descritto più avanti.
Il BUS grigio che si vede a fianco del CNB è il BUS di collegamento unico su cui si affacciano tutti i core e su cui sono abilitati a comunicare, a turno, dal NB.
Il resto del diagramma include uno dei core con le relative cache.
Tecniche di risparmio energetico
Dalla descrizione che segue nelle pagine successive, per chi conosce già la precedente architettura Stars, potrebbe sembrare che non sia poi cambiato molto. In realtà nel core Llano è stata implementata tutta una serie di tecniche avanzate di risparmio energetico.
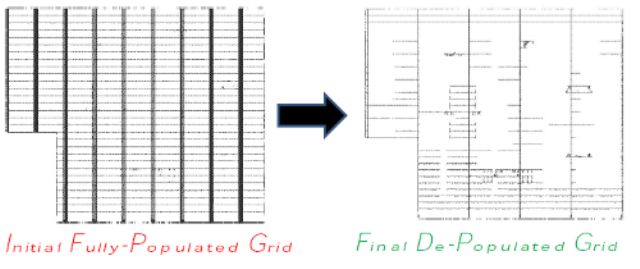
Innanzitutto la griglia che distribuisce il clock è stata ridisegnata completamente e resa sparsa, ossia sono stati eliminati quei rami che non portavano il segnale a nessuna unità. Poi è stato implementato il clock gating alle varie unità e con un granularità molto spinta.
Il clock gating consiste nello spegnimento del clock a parti di un chip per ridurne sensibilmente il consumo.
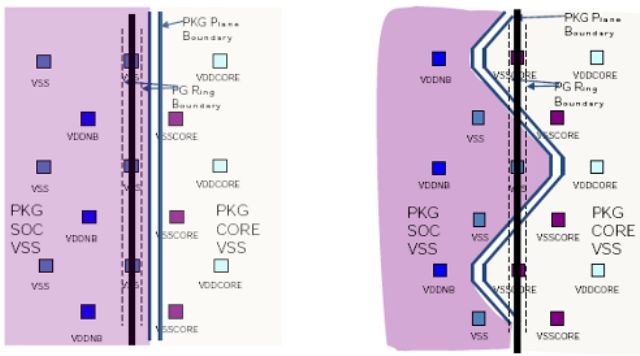
Infine è stato introdotto lo stato di risparmio energetico CC6 che consiste nel togliere fisicamente l’alimentazione a tutto il core, tramite un anello di circa un milione di transistor attorno a ogni core.
E’ stato stimato da AMD che il risparmio di energia è pari al 16% in full load, del 36% in idle e oltre il 90% nello stato di risparmio energetico CC6, rispetto a un core Stars, normalizzando il consumo per il clock, per il processo produttivo e per il numero di transistor.
Ciò vuol dire che se il core Llano fosse stato realizzato con il processo produttivo a 45nm e avesse lo stesso numero di transistor di un core Stars, consumerebbe quanto indicato. E’ stato stimato, inoltre, che, normalizzando il consumo come detto precedentemente, in media, un core Llano consuma il 25% in meno.
Le differenze con il core Stars sono notevoli, soprattutto nello stato di risparmio energetico massimo, che non esiste nei core di vecchia generazione, in quanto un core in idle veniva portato a 800 o 1000 MHz, riducendo ma non azzerando il consumo. In particolare non c’era clock e power gating.
Tutto ciò era possibile grazie all’ottimo processo SOI che è stato ulteriormente migliorato, ma come possiamo vedere, con Llano si è ottenuto ancora di più, grazie all’introduzione di queste nuove tecnologie.
Tali tecniche sulla griglia del clock, sul clock e sul power gating sono state estese anche al North Bridge e soprattutto alla GPU, che beneficia anche del passaggio al processo 32nm HKMG SOI gate first di Global Foundries.

Come è visibile dall’immagine termica, gli anelli di transistor sono molto efficaci nel ridurre la dissipazione del calore. Senza di essi, ma con il solo clock gating, rimarrebbe il leakage, che nei processi SOI è molto basso, fino a 10-20 volte meno della concorrenza. Ma il processo 32nm HKMG SOI e gate first consente di usare nell’anello di transistor gli N-MOS, che sono in grado di ridurre di un ulteriore fattore 10 il già basso leakage.
La concorrenza invece usa un processo gate last, che richiede l’uso dei transistor P-MOS, meno efficaci, per il power gating. Risultato? Le parti spente non assorbono praticamente corrente, e rimangono quasi a temperatura ambiente. Un grande passo in avanti rispetto al core Stars.
Addentrandoci maggiormente nel funzionamento del risparmio energetico, possiamo dire che Llano ha due tensioni di alimentazioni separate: VDD e VDDNB. Sulla prima linea, sono collegati tutti i core, che quindi sono alimentati dalla stessa tensione. Sulla seconda linea sono collegate le restanti unità del chip: il Northbridge, la GPU, il blocco UVD e il blocco GIO.
Apparentemente potrebbe sembrare poco efficiente collegare tutti i core alla stessa tensione di alimentazione, perché il VDD deve essere pari alla tensione massima richiesta da tutti i core. Ma il clock gating spinto, il power gating spinto, lo stato CC6 per i core, il processo di litografia a bassissimo leakage e l’alta efficienza degli N-MOS di spegnimento dei core consentono un consumo quasi nullo per i core non utilizzati.
In realtà esistono due tipi di stato di risparmio energetico C6. Il CC6 (Core C6) è lo stato di risparmio energetico massimo di un singolo core, che abbiamo già visto. Ma se almeno un core è attivo, la tensione VDD e il generatore di clock non possono essere disattivati, consumando energia. Qui entra in gioco il secondo stato di risparmio energetico C6, più profondo, detto PC6 (package C6), che si attiva quanto tutti i core sono nello stato CC6. In questo caso sia la tensione di alimentazione che i clock dei core possono essere spenti, portando a un ulteriore risparmio.
Per quanto riguarda il VDDNB, anche qui un’unica tensione è un compromesso per ridurre la complessità di sistema, ma grazie sempre al clock gating e al power gating molto granulare, il risparmio energetico può essere consistente.
Come per i core, il VDDNB deve essere impostato alla tensione massima richiesta dai componenti alimentati. Il Northbridge ha i suoi P-State, così come la GPU, con il relativo controller di memoria, che è uno dei componenti dal maggior assorbimento e che per questo può essere spento indipendentemente dalla GPU, l’UVD e l’unità GIO (il P-State dipende dalla velocità dei link PCI Express, 1.0 o 2.0, che richiede tensione di alimentazione superiore).
Per quanto riguarda la GPU, essa può essere spenta automaticamente dall’hardware, tramite un timer programmabile da BIOS oppure dal driver grafico stesso. Ma come per i core, il clock gating e il power gating uniti al processo produttivo avanzato, consentono un consumo ottimale, come visibile nella immagine termica precedente.
Altre tecniche di risparmio energetico implementate, consistono nella compressione dei dati del frame buffer, che consente di trasferire meno dati e quindi risparmiare energia e una tecnica implementata nella versione mobile, chiamata adaptive backlight modulation (ABM), che consiste nel modulare la luminosità della lampada di retroilluminazione del display in funzione del contenuto visualizzato, per ridurne il consumo senza alterare in modo visibile le immagini visualizzate.
Architettura delle cache
I core Llano sono dotati di una cache L1 istruzioni, una cache L1 dati e di una cache L2 unificata. E’ stata eliminata la cache L3, rispetto ad alcuni dei core Stars, quindi la struttura della cache ricalca il core Propus. Questo può far perdere qualche punto percentuale in prestazioni, su applicazioni avide di memoria, ma come vedremo più avanti, le migliorie al core, alla cache L2 e al controller di memoria, abbinato a memorie più veloci, compensano in molti casi tale mancanza.
Il motivo della eliminazione della cache L3 è per una questione di risparmio energetico, oltre al risparmio di spazio. L’architettura a cache esclusiva delle CPU AMD implica che quando si deve cercare un dato, esso deve essere cercato nella cache L3 e in tutte le altre cache della CPU. Ma con lo stato di risparmio energetico C6, è possibile che queste debbano essere svegliate, rendendo il tutto molto lento, complicato e dispendioso. In sostanza l’implementazione dello stato C6 sarebbe stata inefficiente con una cache L3.
Un’altra differenza tra le cache di Llano e dei core Stars è che la cache L1 dati è del tipo ad 8 transistor in Llano, contro i 6 della precedente generazione. Le cache ad 8 transistor aumentano, come è intuibile, lo spazio occupato dalle celle, ma consentono una maggiore velocità, una maggiore affidabilità, una minore tensione e quindi un minor consumo.
Cache L1 istruzioni
La cache istruzioni ha dimensioni di 64KB ed è set-associativa a due vie, con linee da 64 byte ognuna. Tale unità si occupa di caricare le istruzioni, effettuarne il prefetching, il pre-decoding, per determinare la fine di una istruzione e l’inizio dell’altra e mantenere le informazioni per il branch prediction.
I dati non presenti in cache sono richiesti alla cache L2 o alla memoria di sistema. In tal caso la cache esegue richieste per due linee di 64 byte naturalmente allineate e consecutive, effettuando in tal modo un prefetch delle istruzioni eventualmente successive, dato che tipicamente il codice presenta località spaziale.
Le linee della cache sono rimpiazzate con l’algoritmo LRU (Least Recently Used, usati meno di recente).
Durante questi riempimenti della cache, le informazioni di pre-decoding, che determinano i confini delle istruzioni, sono generate e memorizzate con le istruzioni in appositi bit. Questo per poter più efficientemente decodificare le istruzioni a valle nel decoder. La cache è protetta solo da bit di parità.
Cache L1 dati
La cache dati ha dimensioni di 64KB ed è set-associativa a due vie, con linee da 64 byte ognuna e con due porte a 128 bit. E’ gestita con la politica del write-allocate (ossia quando si scrive un dato, esso viene conservato in ogni caso nella cache L1) e del write-back (ossia il dato è scritto fisicamente nei livelli inferiori, come cache L2 o memoria RAM, solo quando deve essere eliminato dalla cache).
Le linee della cache sono rimpiazzate con l’algoritmo LRU.
E’ divisa in 8 banchi ognuno di 16 byte. Due accessi nelle due porte sono possibili contemporaneamente solo se sono indirizzati a banchi diversi. La cache supporta il protocollo di coerenza MOESI (Modified, Owner, Exclusive, Shared, and Invalid) e la protezione ECC. Ha un prefetcher che carica in anticipo i dati per evitare miss ed ha una latenza di 3 cicli di clock.
Cache L2
La cache L2 è integrata on die, procede alla stessa frequenza della CPU e ce n’è una per ogni core. Inoltre è una cache con architettura esclusiva: la cache contiene solo linee modificate provenienti dalla L1 che devono essere scritte in RAM e che sono state designate dall’algoritmo LRU per essere eliminate dalla cache L1, perché devono essere rimpiazzate da dati più nuovi. Tali linee sono dette victim (vittime).
La latenza della cache L2 è di 9 cicli di clock in aggiunta a quella della cache L1. In Llano la cache L2 è da 1MB a 16 vie, contro i 512KB a 8 vie della maggior parte dei core Stars (solo il dual core Regor ha cache da 1MB). La cache L2 è protetta con il codice di protezione errore ECC.
Translation-Lookaside Buffer
Il translation-lookaside buffer (TLB) mantiene le più recenti informazioni di traduzione di indirizzi virtuali utilizzate e perciò ne accelera il calcolo.
Ogni accesso in memoria passa per varie fasi. La prima fase è l’indirizzamento. Una istruzione specifica una modalità di indirizzamento che non è altro il procedimento di calcolo per trovare l’indirizzo (lineare anche detto virtuale) di un determinato dato.
Esistono vari metodi di indirizzamento. Il più semplice è l’immediato, in cui il dato è contenuto nell’istruzione stessa. In tal caso non è necessario accedere ulteriormente in memoria. Poi esiste il diretto, in cui nella istruzione è specificato l’indirizzo assoluto del dato. Esistono altri tipi di indirizzamento (indiretto, indicizzato, con offset eccetera) e altre peculiarità della architettura x86-64 (la segmentazione), che richiedono il calcolo, più o meno complicato, dell’indirizzo finale (in genere effettuato nelle AGU, descritte più avanti), ma il risultato finale è un indirizzo lineare o virtuale.
Se la memoria virtuale è abilitata (e nei moderni sistemi operativi lo è sempre), tale indirizzo virtuale deve essere tradotto in un indirizzo fisico. E’ qui che entrano in gioco i TLB. La traduzione dell’indirizzo comporta la divisione dello spazio di indirizzamento in pagine di 4KB (anche se la CPU supporta pagine di 4KB, 2MB, 4MB e 1GB) dove per ognuna sono memorizzate le informazioni di protezione e di posizione fisica dei dati.
Per ogni processo esiste perciò una tabella di pagine, organizzata come un albero a più livelli. Per ogni accesso in memoria si dovrebbe accedere e scorrere tale albero, accedendo alla RAM. Senza i TLB sarebbe un processo molto lento. Invece i TLB fanno da cache alle ultime informazioni di traduzione usate.
Llano usa una struttura di TLB a 2 livelli.
TLB istruzioni di Livello 1
Il TLB istruzioni L1 è completamente associativo, con spazio per 32 traduzioni di pagine da 4KB e 16 per pagine di 2MB. Pagine di 4MB richiedono 2 locazioni da 2MB.
TLB dati di Livello 1
Il TLB dati L1 è completamente associativo, con spazio per 48 traduzioni di pagine da 4KB, 2MB, 4MB e 1GB. Pagine di 4MB richiedono 2 locazioni da 2MB.
TLB istruzioni di Livello 2
Il TLB istruzioni L2 è associativo a 4 vie, con spazio per 512 traduzioni di pagine da 4KB.
TLB dati di Livello 2
Il TLB dati L2 ha spazio per 1024 traduzioni di pagine da 4KB (contro le 512 dei core Stars: questo comporta una maggiore probabilità di trovare la traduzione in cache e la possibilità di gestire il doppio della memoria a parità di prestazioni), associativo a 4 vie, 128 traduzioni da 2MB, associativo a 2 vie e 16 traduzioni da 1GB, associativo a 8 vie. Pagine di 4MB richiedono 2 locazioni da 2MB.
Unità di Fetch e Decodifica
L’unità di fetch e decodifica effettua la traduzione del vetusto e complesso set di istruzioni x86-64 in più maneggevoli macro-ops. Ogni macro-op è in grado di descrivere una operazione aritmetico/logica, intera o in virgola mobile, e contemporaneamente una operazione di memoria, sia essa di lettura, scrittura, e lettura-modifica-scrittura (operazione atomica, utile per implementare i semafori nei kernel dei sistemi operativi).
Llano non si discosta molto dal suo predecessore. Incorpora due decoder separati, uno per decodificare e scomporre istruzioni semplici (fino a 2 macro-op), così dette DirectPath e uno per le istruzioni più complesse, così dette VectorPath (3 o più macro-op).
Quando la finestra istruzioni (che ricordiamo è di 32 byte divisa in due parti da 16 byte) è letta dalla cache istruzioni L1, i byte sono esaminati per determinare se le istruzioni sono di tipo DirectPath o VectorPath (questa è una delle informazioni che fanno parte del pre-decode e che sono memorizzate nella L1). L’output di questi decoder mantiene l’ordine di programma per le istruzioni.
Come vedremo più avanti, Llano è una architettura out-of-order, ossia è in grado di eseguire le istruzioni fuori ordine per una esecuzione più veloce.
Questi decoder possono produrre fino a tre macro-op per ciclo, provenienti esclusivamente da uno dei due tipi di decoder, in ogni ciclo. L’output di questi decoder è unito e passato alla unità seguente, la Instruction Control Unit (ICU unità di controllo istruzioni).
Poiché la decodifica di una istruzione VectorPath produce almeno 3 macro-op ed è possibile mandare all’ICU solo le macro-op di una unità alla volta, la decodifica di istruzioni VectorPath ferma quella delle istruzioni DirectPath. Le istruzioni DirectPath che possono essere decodificate in un ciclo dipendono dalla complessità delle stesse.
Il decoder DirectPath è in grado di decodificare ogni combinazione di istruzioni x86 di tipo DirectPath che si traduce con una sequenza di 2 o 3 macro-op, considerando che la decodifica avviene in ordine di programma. Quindi sono possibili 3 istruzioni se ci sono 3 istruzioni consecutive da una macro-op, cosiddette DirectPath Single. 2 istruzioni sono possibili se una è DirectPath Single e l’altra è DirectPath Double (così sono chiamate le istruzioni semplici che generano due macro-op). E’ possibile la decodifica di una sola istruzione se ci sono due istruzioni DirectPath Double consecutive, che non possono essere decodificate assieme in quanto produrrebbero 4 macro-op, oltre il limite di 3 dell’architettura.
Un altro limite alla quantità di istruzioni decodificabili è dato dal fatto che in un dato ciclo può essere acceduto un solo blocco di 16 byte, dei 32, alla volta e quindi possono essere decodificate solo le istruzioni contenute in tale blocco. Poiché ci sono alcune istruzioni che occupano fino a 15 byte, è possibile che in un blocco di 16 byte non siano presenti un numero di istruzioni sufficienti a impegnare tutto il decoder.
Branch Prediction
La predizione dei salti in Llano funziona allo stesso modo della precedente generazione. Un nuovo salto è predetto come non preso finché non è effettivamente preso una volta. Successivamente il salto è predetto come preso finché questa previsione non è effettivamente sbagliata. Dopo queste due previsioni sbagliate, la CPU inizia ad usare la Branch Prediction Table (BPT, tavola di predizione dei salti).
La logica di fetch accede alla cache L1 istruzioni e alla BPT in parallelo e le informazioni nella BPT sono usate per predire la direzione di salto. Quando le istruzioni sono spostate nella cache L2, le informazioni di pre-decode e i selettori di salto (che indicano in quale condizione il salto sia, ossia mai visto, preso una volta, preso e poi non preso) sono copiate con esse e memorizzate al posto del codice ECC.
La tecnica di predizione dei salti è basata su una combinazione di un branch target buffer (BTB, buffer delle destinazioni di salto predette) di 2048 elementi e di un global history bimodal counter (GHBC, contatore bimodale storico globale) di 16384 elementi a 2 bit che contengono un contatore a saturazione usato per prevedere se un salto condizionale deve essere predetto come preso. Questo contatore contiene quante volte nelle ultime 4 esecuzioni il salto è stato preso e dunque il salto è predetto come preso se almeno 2 volte è stato preso di recente.
La GHBC è indirizzata con una combinazione di un numero non specificato di risultati degli ultimi salti condizionali e l’indirizzo di salto. Questa è una tecnica standard di predizione che prevede l’indirizzamento della tabella con un hashing dell’indirizzo di salto combinato con l’esito degli ultimi n salti.
Il branch prediction include anche un return address stack (RAS, stack di indirizzi di ritorno) di 24 elementi per predire le destinazioni di chiamate a procedura e ritorno da procedura. Infine è presente una tabella di 512 elementi per predire i salti indiretti, anche con destinazioni multiple.
Sideband Stack Optimizer
Tale unità tiene traccia del registro stack-pointer (puntatore allo stack). In tal modo possono essere eseguite in parallelo varie istruzioni che richiedono in ingresso tale registro (CALL, RET, PUSH, POP, indicizzazione tramite lo stack pointer, calcoli che hanno come registro sorgente lo stack pointer).
Istruzioni che non possono essere eseguite in parallelo sono quelle che hanno come destinazione lo stack-register, quelle di indirizzamento indicizzato (in cui sono fatti calcoli su tale registro) e le istruzioni di tipo VectorPath che usano in qualche modo tale registro (per la difficoltà di tenere traccia del registro in istruzioni VectorPath).
Instruction Control Unit
La ICU è il centro di controllo del processore. Controlla il registro centralizzato di riordino per le istruzioni in esecuzione e gli scheduler interi e floating point.
E’ responsabile del dispatch (ossia dell’inoltro all’opportuno scheduler) delle macro-op, del ritiro (ossia della determinazione e validazione del risultato) delle macro-op, della risoluzione delle dipendenze dei registri e dei flag, tramite il renaming (una tecnica per poter eseguire in parallelo istruzioni scorrelate ma che accedono allo stesso registro), della gestione delle risorse di esecuzione, delle interruzioni, eccezioni (durante il ritiro delle macro-op) e della gestione della predizione errata dei salti, che comprende lo svuotamento delle varie code e l’annullamento delle operazioni in corso.
L’ICU prende fino a 3 macro-op per ciclo, prodotte dal decoder precedentemente e le inserisce in un buffer di riordino centralizzato, composto da 28 linee di 3 macro-op, che costituiscono un incremento rispetto alle 24 della precedente architettura Stars. Questo incremento può dare maggior respiro al decoder a monte, in quanto se a valle le istruzioni non sono eseguite per mancanza di dati dalla memoria, ad esempio, questa coda si riempie rapidamente. Incrementarla diminuisce il tempo di stallo del decoder, che si deve fermare se tale coda è piena.
Questo buffer consente di tener traccia di un massimo di 84 macro-op, sia intere che floating point. L’ICU può inoltrare simultaneamente le macro-op ai vari scheduler interi o floating point, che faranno la decodifica finale e l’esecuzione delle macro-op.
Una volta completata l’esecuzione, è sempre l’ICU che effettua il ritiro, in ordine di programma, delle istruzioni e ne gestisce le eventuali eccezioni, compresa la predizione errata di un salto
E’ da notare che le varie macro-op possono venire eseguite fuori ordine e in parallelo, sia all’interno della stessa unità (intera o floating point), sia se eseguite su unità diverse. Il dispacth e il retire avvengono, invece, in ordine di programma.
Unità intera
Essa contiene due componenti, lo scheduler intero, e le unità di esecuzione intera.
Scheduler intero
Esso è basato su un sistema di accodamento a 3 vie, chiamato anche reservation station (RS) che rifornisce le tre unità di esecuzione. Ognuna delle 3 code ha posto per 10 macro-op (8 nella precedente architettura Stars: code più lunghe significano maggiore possibilità di riordino delle istruzioni e quindi maggiori prestazioni) per un totale di 30 macro-op gestibili. Ogni RS suddivide la macro-op nelle sue componenti aritmetico logiche e di generazione indirizzo.
Unità di esecuzione intera
L’unità di esecuzione intera (IE) si compone di 3 elementi (pipeline 0, 1 e 2). Ogni elemento è composto da una unità aritmetico logica (ALU) e una unità di generazione indirizzo (AGU). La IE è organizzata in modo da collimare con le 3 pipeline di dispach delle macro-op della ICU, come visibile in figura.
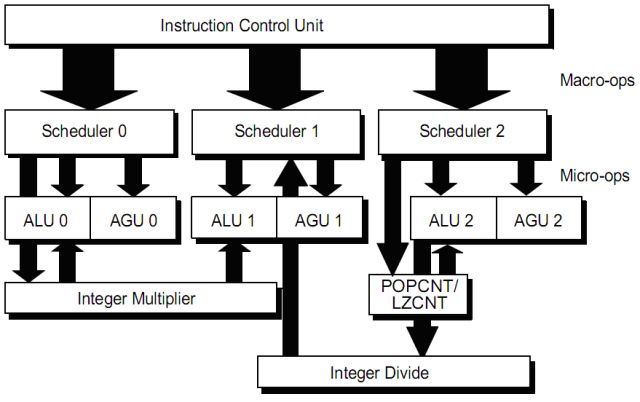
Le macro-op sono spezzate in micro-op negli scheduler. Le micro-op sono eseguite quando i relativi operandi sono disponibili sia nei registri che nei bus dei risultati: in alcuni casi di istruzioni interdipendenti, non è necessario scrivere prima il risultato in un registro e poi leggerlo nel ciclo successivo, ma è possibile collegare le due istruzioni tramite uno dei bus di risultato disponibili.
Le micro-op provenienti da una singola macro-op possono essere eseguite fuori ordine ed inoltre una particolare pipeline intera può eseguire micro-op provenienti da macro-op diverse (una nella ALU e una nella AGU) contemporaneamente.
Ognuna delle tre ALU è in grado di eseguire istruzioni logiche, aritmetiche, funzioni condizionali, elaborazione dei flag di stato e calcolo dello stato di un salto.
Ognuna delle tre AGU è in grado di calcolare l’indirizzo lineare per un accesso in memoria o per l’istruzione LEA (che calcola l’indirizzo effettivo di un dato senza effettuare l’accesso in memoria. LEA sta infatti per Load Effective Address, ossia calcola e carica l’indirizzo effettivo).
E’ presente una unità per le letture e scritture in memoria, che accede effettivamente alla cache L1 dati, descritta più avanti (LSU, load and store unit).
Lo scheduler intero manda un segnale di completamento all’ICU per segnalare che una macro-op è stata eseguita. L’ICU ritirerà l’istruzione quando tutte le relative macro-op sono state eseguite.
Quasi tutte le operazioni intere possono essere eseguite indifferentemente dalle 3 ALU, con l’eccezione di moltiplicazione, divisione, LZCNT (leading zero count, ossia conteggio degli zero iniziali di un numero binario) e POPCNT (population count, ossia conteggio degli ‘1’ presenti in un numero binario).
Le moltiplicazioni sono gestite da un moltiplicatore pipelined, che è alimentato dalla pipeline 0. Per eseguire una moltiplicazione, però le pipeline 0 e 1 sono tenute bloccate simultaneamente, poiché il risultato di tutte le operazioni di moltiplicazione nella architettura x86 è a doppia precisione e richiede la specifica di due registri di destinazione. Durante l’esecuzione, le due pipeline 0 e 1 non possono essere usate se non per altre moltiplicazioni (perché il moltiplicatore è pipelined). Il moltiplicatore di Llano è stato ulteriormente migliorato rispetto alla precedente generazione di core Stars.
Analogamente la divisione usa le pipeline 1 e 2 e il divisore intero è alimentato dalla pipeline 2, poiché la divisione nella architettura x86 parte da dati a doppia precisione e fornisce risultato e resto in due registri separati. Durante l’esecuzione le due pipeline 1 e 2 non possono essere usate se non per altre divisioni (perché il divisore è pipelined).
Nella precedente architettura (core Stars) non esisteva un divisore hardware, ma la divisione era una lunga istruzione VectorPath che bloccava le pipeline 1 e 2 per tutto il tempo della sua lunga esecuzione (in Llano le divisioni sono anche il doppio più veloci) e non essendoci un divisore pipelined, poteva essere effettuata una divisione alla volta.
Le istruzioni LZCNT e POPCNT sono eseguite in una unità alimentata dalla pipeline 2 e finché è in esecuzione una di queste istruzioni la pipeline 2 non è utilizzabile da altre istruzioni diverse da queste due (perché l’unità è pipelined).
In definitiva una moltiplicazione blocca l’esecuzione di tutte le istruzioni non moltiplicative nelle pipeline 0 e 1 e anche di tutte le divisioni, che richiedono anche la pipeline 1 per funzionare. La divisione blocca l’esecuzione di tutte le istruzioni non di divisione nelle pipeline 1 e 2 e quindi anche le moltiplicazioni, che richiedono la pipeline 1, e le istruzioni LZCNT e POPCNT bloccano tutte le istruzioni che richiedono la pipeline 2 e quindi anche le divisioni.
Unità Floating Point
L’unità Floating Point (FPU) contiene due componenti, lo scheduler floating point, e le unità di esecuzione floating point
Scheduler Floating Point
Lo scheduler è in grado di accettare 3 macro-op per ciclo in qualsiasi combinazione tra le istruzioni supportate che sono: x87 floating-point, 3DNow!, MMX, SSE1/2/3/4a.
Esso gestisce il register renaming ed ha un buffer di tre code da 14 elementi ciascuno, per un totale di 42 elementi (la precedente architettura Stars aveva 3 code da 12 elementi per un totale di 36 macro-op: anche qui code più lunghe significano prestazioni maggiori).
Esso esegue anche il superforwarding, che consiste nell’inoltrare i risultati di una operazione di lettura dalla memoria alle operazioni dipendenti nello stesso ciclo di clock, senza aspettare la scrittura nei registri, come avviene per il regolare forwarding che avviene normalmente sia in questa unità che nella unità intera, tramite l’uso dei bus di risultato.
Inoltre esegue l’inoltro delle micro-op, e l’esecuzione fuori ordine. Lo scheduler comunica anche con l’ICU per ritirare le istruzioni completate, per gestire i risultati delle varie istruzioni di conversione floating point ad intero e viceversa (le due unità intere e floating point usano per comunicare un bus da 64 bit) e per ricevere i comandi di annullamento dei risultati dovuti alla predizione errata di un salto.
Unità di esecuzione floating point (FPU)
La FPU gestisce tutte le operazioni su registri del set di istruzioni x87, 3DNow!, MMX e SSE1/2/3/4a.
La FPU comprende una unità di rinominazione dello stack (poiché le istruzioni x87 lavorano non con registri ma con una architettura a stack di 8 elementi, ereditata dalle prime FPU esterne x87) che consente di tradurre l’accesso a stack in un accesso a uno degli 8 registri, una unità di register renaming convenzionale, uno scheduler, un register file, contenente i registri fisici e le unità di esecuzione capaci di elaborare ognuna fino a 128 bit per ciclo di clock. In figura è riportato un diagramma a blocchi per il flusso di dati della FPU.
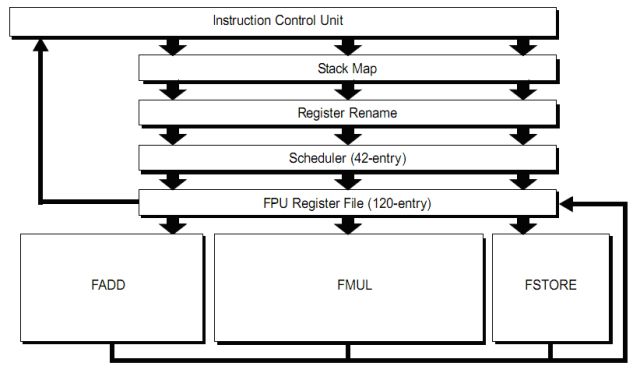
Come è visibile in figura la FPU è composta da 3 unità (FADD, FMUL, and FSTORE).
L’unità FADD è in grado di eseguire tutte le istruzioni di addizione e sottrazione, sia intere SIMD (3DNow!, MMX e SSEn), sia floating point, nonché i tipi di movimento tra registri e gli shuffle (scambio) ed extract SSEn.
L’unità FMUL è in grado di eseguire tutte le istruzioni di moltiplicazione, divisione, inverso, radice quadrata e trascendenti sia intere SIMD (3DNow!, MMX e SSEn), sia floating point, nonché i movimenti tra registri e alcuni tipi semplici di shuffle ed extract.
L’unità FSTORE è utilizzata, da sola o in tandem, in ogni istruzione che richiede un accesso in memoria ed è anche in grado di effettuare i movimenti tra registri.
Unità di lettura e scrittura
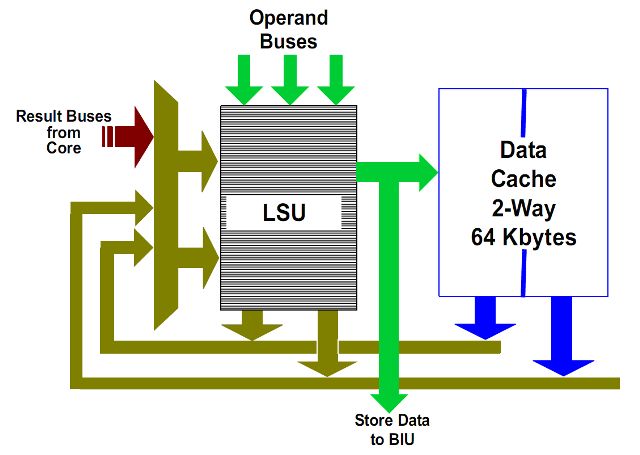
Load-Store Unit, LSU
La cache L1 dati e la LSU sono mostrate in figura. La cache L1 dati supporta fino a 2 operazioni di lettura a 128 bit per ciclo oppure due scritture a 64 bit per ciclo o una mistura di queste due.
La LSU è composta di due code, LS1 di 24 elementi e LS2 di 64 elementi (12 e 32 nella precedente architettura Stars).
L’unità LS1 può iniziare due operazioni sulla cache L1 (letture oppure controllo dei tag per una successiva scrittura, ricordando che la cache usa politica di write allocate, quindi bisogna controllare se il dato è presente in cache prima di scriverlo) per ogni ciclo di clock. Può iniziare le operazioni di lettura fuori ordine, a patto che siano verificate certe condizioni.
La coda LS2 contiene le richieste che hanno dato un miss nella cache L1 dopo il controllo effettuato dalla unità LS2. Le scritture sono effettuate comunque a partire dalla coda LS2, quindi in essa andrà il risultato del check dei tag.
Le scritture a 128 bit sono trattate in modo speciale, poiché è possibile scrivere 64 bit alla volta, e occupano due posti nella LS2.
Infine la LSU si assicura che le regole di ordinamento delle operazioni in memoria della architettura x86 siano rispettate.
Write Combining
Llano ha 4 buffer da 64 byte (una linea di cache) e 8 buffer indirizzo per poter fondere fino a 8 scritture verso 4 linee diverse di cache.
Quando più scritture sono eseguite a poca distanza, può essere utile combinarle assieme prima di eseguire la scrittura completa per migliorare l’efficienza di scrittura.
Tale caratteristica è particolarmente utile quando i dati da scrivere sono verso dispositivi esterni collegati tramite il bus PCI Express o verso il south bridge.
North Bridge, GIO e Controller Memoria
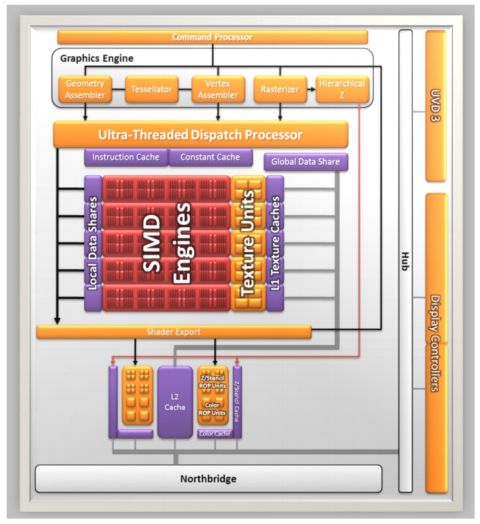
In figura è visibile uno schema a blocchi semplificato del cuore dell’architettura di Llano, ossia i componenti che smistano i dati e gestiscono le comunicazioni con l’esterno: il North Bridge, l’unità GIO e il controller della memoria.

Il blocco di colore verde, contenente gli elementi chiamati IFQ/FE, XBAR, Front End (DFE), DRAM, Back End (DBE), GIO, Garlic Interface e Onion Interface, costituiscono il north bridge on chip, abbreviato in CNB.
Il blocco giallo, chiamato CIF è un blocco di sincronizzazione tra il CNB e ogni core, che convoglia e unifica il flusso di dati da e verso i core con il CNB. Il suo compito è di implementare l’interfaccia CCI, Common Core Interface, Interfaccia comune per i core, che è il punto di accesso unico al CNB per tutti i core.
Questo blocco è quello che implementa l’algoritmo che decide quale dei core può parlare in un dato momento e smista le richieste provenienti da altre parti del chip ai core, come ad esempio il probing delle cache, che è effettuato per vedere se nelle cache dei core è presente un dato più aggiornato rispetto alla memoria RAM.
Veniamo ora ai blocchi costituenti il CNB.
Il blocco IFQ/FE contiene la coda delle richieste delle CPU e della GPU nella IFQ che è dunque una coda unificata.
Comprende anche un blocco di logica, chiamato Front End (FE) che si occupa di gestire le richieste di trasferimento dati da e per i core (che passano per l’interfaccia CCI), di gestire le richieste di trasferimento dati tra l’interfaccia Onion e le CPU, di gestire le richieste di probing della cache delle CPU da parte dei vari componenti e di mantenere la coerenza e la consistenza tra le varie unità.
Il blocco XBAR è il cosiddetto crossbar switch, ossia l’unità che consente il collegamento tra le varie unità collegate al CNB.
E’ in pratica un commutatore digitale che ad ogni istante collega mittente e destinatario di una comunicazione, tra i vari attori presenti nel sistema, come l’interfaccia CCI, il controller RAM, le interfacce Onion e Garlic, eccetera.
I blocchi DRAM, DBE e DFE fanno parte del memory controller (MC).
Il blocco DFE, detto Data Front End, si occupa di selezionare le richieste da mandare alla restante parte del controller RAM e decide tra richieste Onion (coerenti), Garlic (non coerenti) e CCI (coerenti).
Le richieste sono materialmente eseguite dal blocco DBE, detto Data Back End, che sincronizza il CNB con l’interfaccia fisica alle memorie DRAM e gli manda i comandi di trasferimento.
L’interfaccia Garlic (che tradotto letteralmente significa “Aglio”) è un collegamento bidirezionale e a bassa latenza, quindi diretto, tra la GPU e il Data Back End del controller RAM.
Quando il Data Front End ha dato il consenso, la GPU può comunicare con il controller RAM in modo diretto.
L’interfaccia Onion (che tradotto letteralmente significa “Cipolla”) è un collegamento bidirezionale tra la GPU è la coda IFQ. E’ usata per collegare la GPU alle CPU.
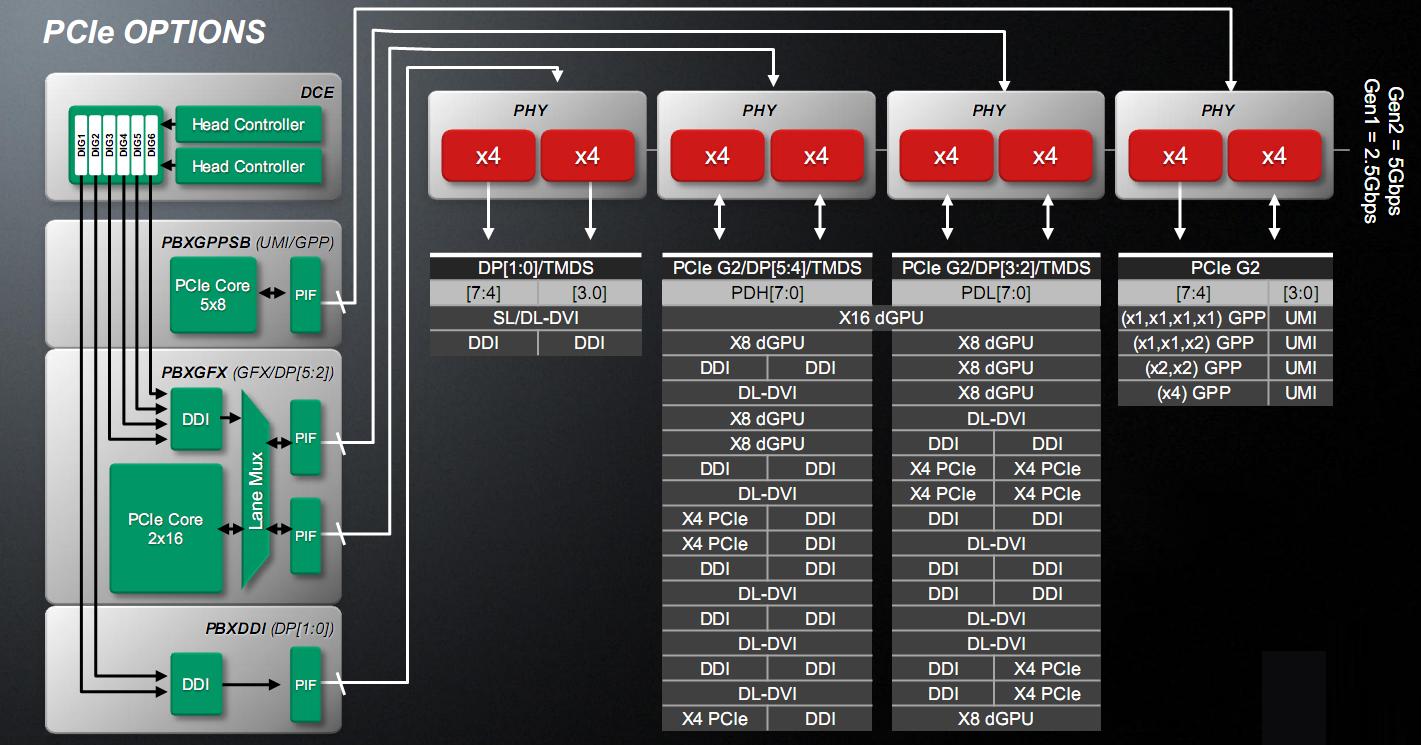
Il blocco indicato con GIO (Graphics and I/O) è il blocco che gestisce l’I/O del chip, ed è collegato alla unità XBAR del North Bridge (CNB) per comunicare con i core e il controller RAM e ha un collegamento diretto e privilegiato con la GPU. Questo perché gestisce il controller PCI Express fino a 32 linee, configurabile in vari modi.
Quattro linee sono riservate all’interfaccia UMI (Unified Media Interface), che non è altro che una interfaccia PCI Express a 4 linee dedicata al collegamento con il Fusion Controller Hub (FCH, il south bridge).
Quattro sono riservate per periferiche PCI Express varie, come le schede audio aggiuntive, per non dover gravare sull’FCH e sono configurabili come linee singole, linee doppie, due singole e una doppia o una sola interfaccia x4.
Sedici linee sono utilizzabili per schede video discrete, configurabile in una interfaccia x16 o due interfacce x8, per il CrossFire.
In alternativa le interfacce x8 possono essere configurate come uscite video, per poter usare la tecnologia EyeFinity, perdendo la possibilità del CrossFire/DualGraphics.
Le rimanenti 8 linee sono utilizzate per implementare le interfacce video HDMI, DVI e Display Port.
Il BUS grigio che si vede a fianco del CNB e del CIF è il BUS di collegamento unico su cui si affacciano tutti i core e su cui sono abilitati a comunicare, a turno, dal blocco CIF.
Controller RAM integrato
Il controller RAM di Llano supporta due canali indipendenti a 64 bit di RAM DDR3 con chip da 8 e 16 bit, supporta l’interleaving sui chip e sui canali, utile per incrementare le prestazioni, leggendo dati consecutivi da chip diversi in parallelo, include algoritmi di scheduling per l’apertura e chiusura delle pagine di memoria, ottimizzato in particolare per flussi di scrittura e lettura intervallati, include algoritmi di scheduling per ottimizzare i flussi intervallati di dati dalle interfacce CPU+Onion e Garlic e include un prefetcher hardware.
In particolare le pagine usate dagli accessi GPU sono chiuse immediatamente, perché in genere gli accessi sono streaming, per liberare le pagine per gli accessi CPU, tipicamente più variegati.
I dati caricati dal prefetcher sono mantenuti nel controller stesso e non sono mandati speculativamente nelle cache L1 e L2.
Il prefetcher è in grado di catturare sia andamenti crescenti o decrescenti di accesso anche con spaziatura non unitaria, utilizzando come unità di misura la linea di cache (64 byte) ed è in grado di rilevare anche sequenze separate di accessi. Inoltre Llano può tenere traccia di 8 sequenze di accessi contemporaneamente (l’architettura Stars ne può tenere traccia di 5).
Il controller della memoria di Llano è stato migliorato di molto rispetto ai core Stars. E’ stata migliorata l’efficienza interna e gli algoritmi di prefetching, in particolare il core Llano è in grado di riconoscere meglio i pattern di accesso alla memoria, perché è in grado di associarvi l’effettiva istruzione che accede alla memoria (IP-based prefetching) e quindi non è più distratto da altre istruzioni intermedie. Inoltre sono stati aumentati i buffer interni.
E’ stata incrementata la frequenza RAM supportata fino a 1866 MHz (solo con una DIMM per canale), rispetto ai 1333 MHz della precedente generazione. In compenso è stato tolto il supporto alle memorie DDR2, ai chip a 4 bit e alla correzione ECC, quest’ultima utilizzata tipicamente in ambito server.
Test CPU: sistema e metodologia di test
Di seguito riportiamo la tabella contenente le specifiche tecniche del sistema utilizzato per effettuare i test del processore.
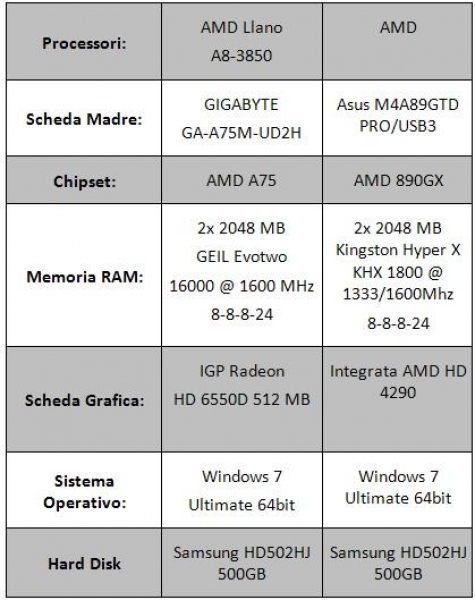
I test sono stati effettuati alla frequenza di default per il Phenom II 945, pari a 3GHz, e a 3016MHz (104MHz per la frequenza di bus e 29 per il moltiplicatore) per Llano. Il Phenom II 840 è stato downcloccato via moltiplicatore a 3GHz (la frequenza di default è 3.2GHz). La memoria RAM è stata impostata a 1600 MHz con latenze 8-8-8-24 per Llano e il Phenom II 840 e a 1333 con latenze 8-8-8-24 per il Phenom II 945.
Di seguito riportiamo i software utilizzati per il test CPU:
SINTETICI
3DMark Vantage: prodotto dalla Futuremark, 3Dmark Vantage è uno strumento utile per testare le prestazioni del proprio sistema. Principalmente ideato per rilevare le prestazioni del comparto grafico il 3DMark Vantage si rivela adatto anche per il testing delle CPU che sempre più spesso fanno da collo di bottiglia nei sistemi quando si parla di applicazioni grafiche. Il test è stato effettuato solamente per quanto riguarda la CPU, disabilitando i 2 step relativi esclusivamente alla vga.
PCMark Vantage: altro celebre benchmark prodotto da Futuremark che ha il compito di analizzare le performance dell’intero sistema. I test effettuati sono relativi alla CPU e comprendono: la crittografia dei dati, decrittografia, compressione, decompressione dati, manipolazione delle immagini attraverso la CPU, transcodifica audio, video transcodifica e molti altri test.
AIDA64: Aida64 è un software prodotto dalla FinalWire che consente di monitorare il sistema fornendoci informazioni dettagliate sulla componentistica hardware. Il software comprende al suo interno un’utility di bench in grado di testare memoria e le cache presenti all’interno del processore.
COMPRESSIONE DATI E MULTIMEDIA
7zip 9.20: questo noto software di gestione degli archivi contiene al suo interno un tool in grado di analizzare le prestazioni di sistema, riportando un valore espresso in MIPS (million instructions per second). Il test comprende compressione, decompressione e valore generale.
Winrar 4 beta 3: altro famoso software di compressione e decompressione di archivi di dati. Al suo interno è presente una utility di benchmark che comprime un file standard atto a tale scopo; il software provvede a restituire il valore di compressione espresso in KB/s.
Cinebench 11.5 e 10: software prodotti dalla Maxon che permettono, tramite l’elaborazione di immagini e di contenuti tridimensionali, di testare le performance della CPU. Entrambe le release permettono il test della CPU utilizzando un core singolo oppure tutti i core presenti all’interno del processore.
X264 Benchmark HD 3.0: software in grado di misurare le performance della CPU mediante la codifica video x264.
Handbrake 0.9.5: software di transcodifica video multithread con il quale trasformeremo un file (un film) in MP4; il processo comprende codifica video x264, codifica audio FAAC e mux finale in contenitore MP4. Verrà preso in considerazione il tempo impiegato dalla CPU per svolgere questo compito.
Test Sintetici
3DMARK VANTAGE
Iniziamo i nostri test partendo dal benchmark prodotto da Futuremark; il 3DMark Vantage. Il test è stato effettuato selezionando solamente i due step relativi alla CPU ed impostando il preset su Performance.
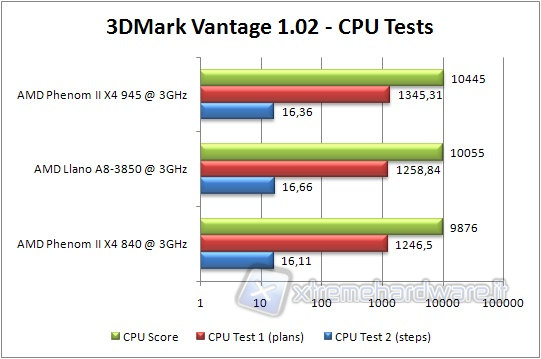
Llano si pone a metà strada tra il Phenom II 840 e il Phenom II 945, come prevedibile. La differenza tra i test CPU 1 e 2 è probabilmente dovuta al maggiore o minore impegno della memoria, dove la cache L3 può fare la differenza.
PCMARK VANTAGE
Proseguiamo con l’altro benchmark di Futuremark; il PCMark Vantage. In questo caso è stata selezionata solo la PCMark Suite.
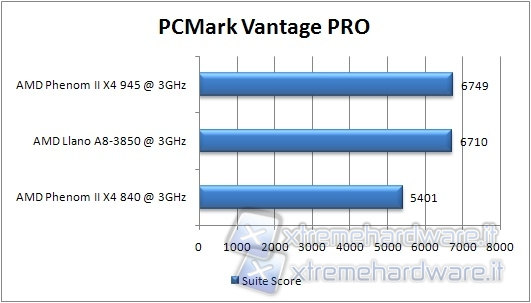
Anche in questo test Llano si pone tra le due CPU di vecchia generazione, ma questa volta la cache L2 e gli altri miglioramenti lo portano a ridosso del Phenom II 945.
AIDA64 EXTREME ENGINEERING
Passiamo al software di FinalWire.
Lanciamo il benchmark relativo a memoria e cache, ricordando che per quanto riguarda le latenze, un valore inferiore è pari a una performance migliore.
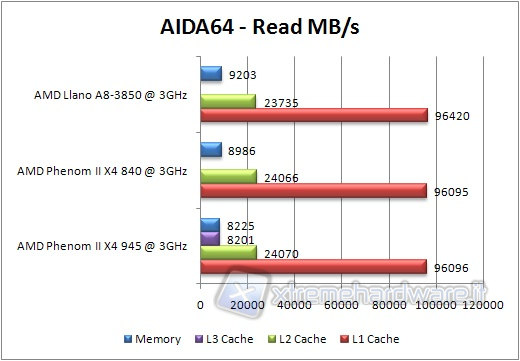
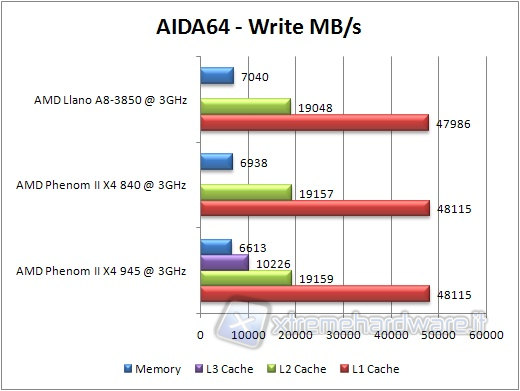
La velocità di lettura in memoria è leggermente superiore a quella del core Propus, grazie alle migliorie al controller RAM. Si posiziona all'utimo posto il Phenom II 945, a causa della frequenza inferiore delle sue RAM. Per quanto riguarda le cache, a parte l'assenza del valore per la cache L3, non si rilevano differenze degne di nota, segno che la nuova architettura non è molto differente dalla vecchia sotto questo punto di vista.
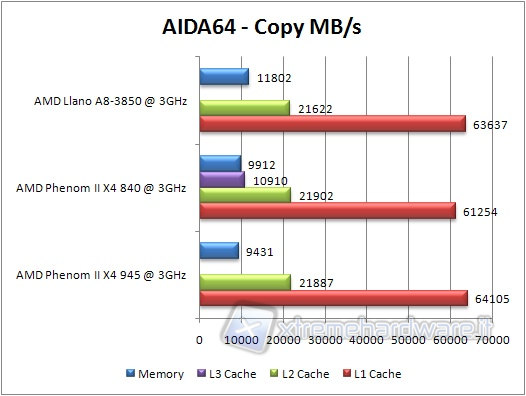
Passando alla velocità di copia, notiamo finalmente notevoli differenze sulla copia in RAM, rispetto alle precedenti architetture, grazie alle migliorie al controller. Si posiziona di nuovo all'ultimo posto il Phenom II 945, a causa della frequenza inferiore delle sue RAM. Per quanto riguarda le cache, a parte l'assenza del valore per la cache L3, non si rilevano ancora differenze degne di nota.
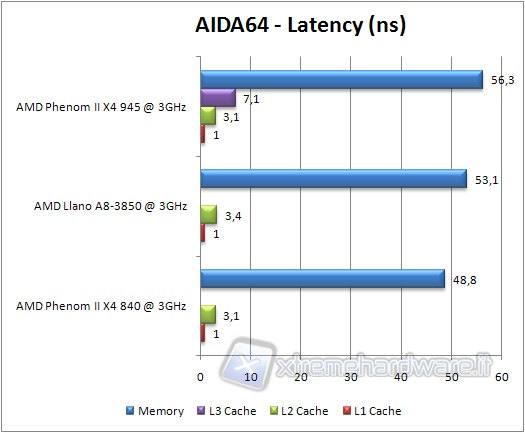
Considerando, infine, il test sulla latenza, notiamo che Llano perde rispetto a Propus, probabilmente a causa dell'overhead per la gestione della GPU. Si posiziona di nuovo all'ultimo posto il Phenom II 945, a causa della frequenza inferiore delle sue RAM. Per quanto riguarda le cache, a parte l'assenza del valore per la cache L3, non si rilevano ancora differenze degne di nota.
Test compressione dati & multimedia
7zip 9.20
Passiamo ai benchmark relative alla compressione, decompressione file e multimedia partendo da un noto programma di gestione di archivi: 7zip.
Lanciamo il tool di misurazione delle prestazioni e verifichiamo i valori, espressi in MIPS, che il software riporta.
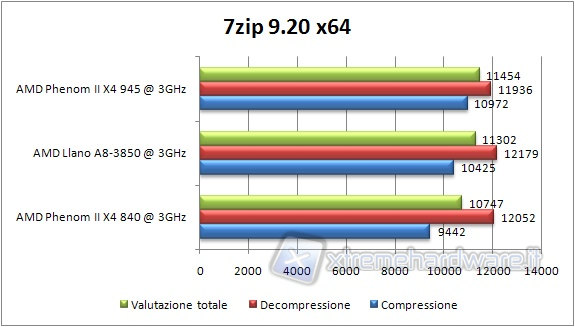
Llano si piazza a metà strada tra i due Phenom ed è superato in compressione dal Phenom II 945 nonostante la velocità inferiore delle sue RAM. In questo caso la cache L3 aiuta. Tanto è vero che il Phenom II 840 è in difficoltà. Per quanto riguarda la decompressione, la banda verso la memoria qui conta di più e quindi il Propus e Llano hanno la meglio.
WINRAR 4 beta 3
Il benchmark presente in Winrar prevede la compressione di un file prestabilito dal software, riportando un valore espresso in KB/s.
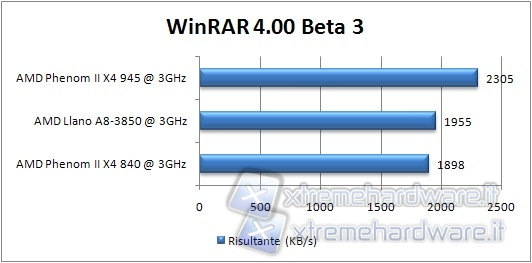
Stesso comportamento relativo di 7zip delle varie CPU in Winrar.
CINEBENCH 11.5
Lanciamo Cinebench 11.5, in grado di testare le prestazioni di una CPU tramite la manipolazione e l’elaborazione di immagini.
Tale software, così come la versione 10, è altamente parallelizzata e sfrutta a pieno tutti i processori presenti nel sistema.
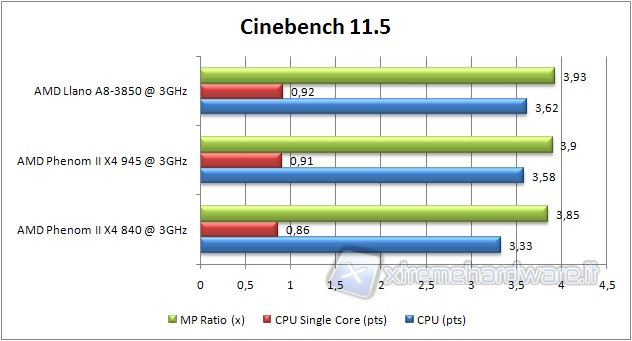
Questa volta le migliorie varie e alla cache L2 sorpassano la perdita di prestazioni dovuta alla mancanza della cache L3. Llano, quindi, si piazza al primo posto. Infine, nonostante le RAM più lente, il Phenom II 945 sorpassa il Phenom II 840.
CINEBENCH 10
Anche questo benchmark utilizza a pieno le tecnologie multicore.
Analizziamo i dati registrati.
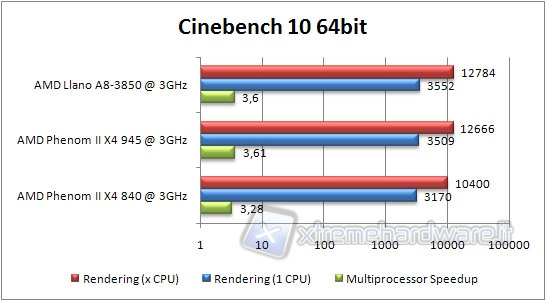
Anche qui stesso discorso del Cinebench 11.5, sebbene con differenze molto minori.
X264 BENCHMARK HD
Questo benchmark permette la valutazione delle prestazioni convertendo un file prescelto nel formato x264.
Tale operazione viene svolta in quattro passaggi da due step ciascuno.
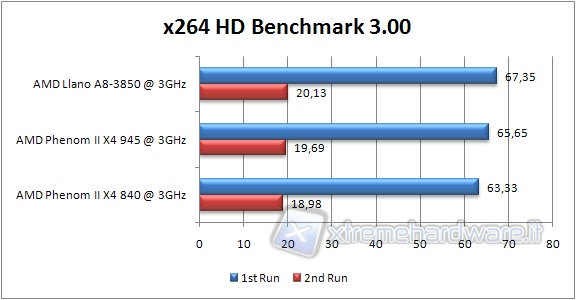
Anche qui stesso discorso del Cinebench 11.5, ma questa volta le differenze sono del 3% tra primo e secondo posto.
HANDBRAKE
Lanciamo Handbrake con il compito di trasformare in MP4 un filmato di 698MB verificando quale processore impiega meno tempo a completare l’operazione; in tal caso un valore inferiore nel grafico è indice di una prestazione superiore.
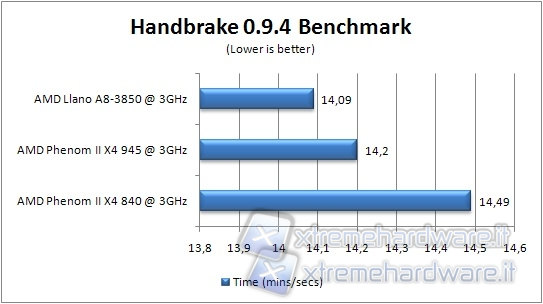
Considerazioni sui test CPU
Nei test sintetici e di compressione, Llano guadagna rispetto al core Propus, per le varie migliorie apportate al core, ma perde leggermente rispetto al Phenom II 945, a causa della mancanza della cache L3, poichè tali test sono più dipendenti dalla memoria, dove la cache L3 e una minore latenza dovuta all'assenza di una GPU possono fare differenza. Llano invece primeggia nelle applicazioni multimediali, dove è importante sia una maggiore potenza di calcolo, sia una maggiore efficacia nel prefetching e nello streaming dei dati verso la memoria, dove il controller RAM migliorato da del suo meglio. Nei test sintetici, invece, i dati sono in genere acceduti con pattern più casuali e riusati abbastanza spesso. Quindi una maggiore cache totale può portare a dei benefici.
GPU
La componente GPU del chip Llano, nome in codice “Sumo”, riprende molte delle caratteristiche della famiglia di GPU “Redwood” di AMD, implementata nelle serie Radeon 5500 e Radeon 5600.
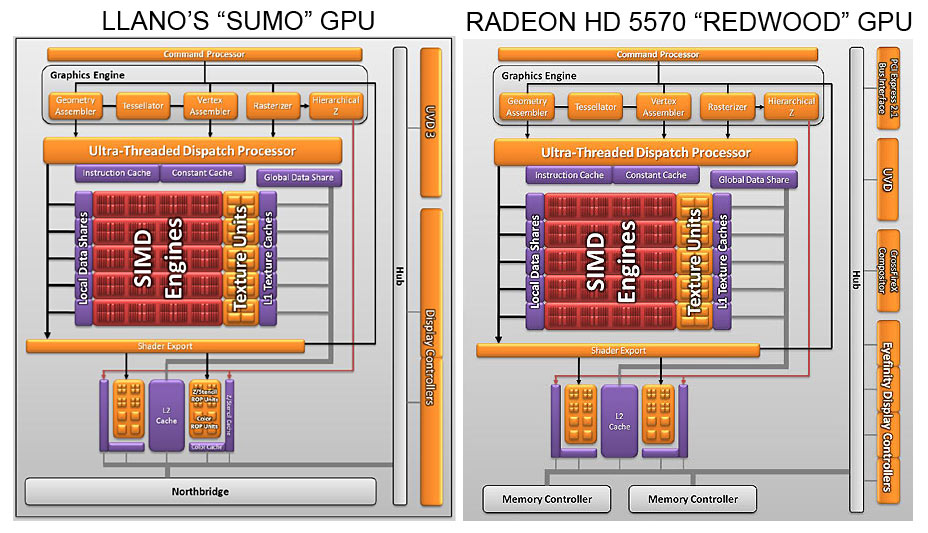
Dal confronto delle due immagini, si nota che non è cambiato molto tra “Sumo” e “Redwood” nel cuore di elaborazione. Abbiamo i SIMD engines, 5 in totale, ognuno composto da 16 thread processor e 4 texture unit.
Ogni thread processor è composto da una unità con architettura VLIW 5, capace di eseguire fino a 5 operazioni per ciclo di clock, dando così un totale di 400 operazioni di calcolo e 20 operazioni su texture per ogni ciclo di clock. In più sono presenti due render back-end, ciascuno capace di 4 operazioni raster (ROP) per ciclo.
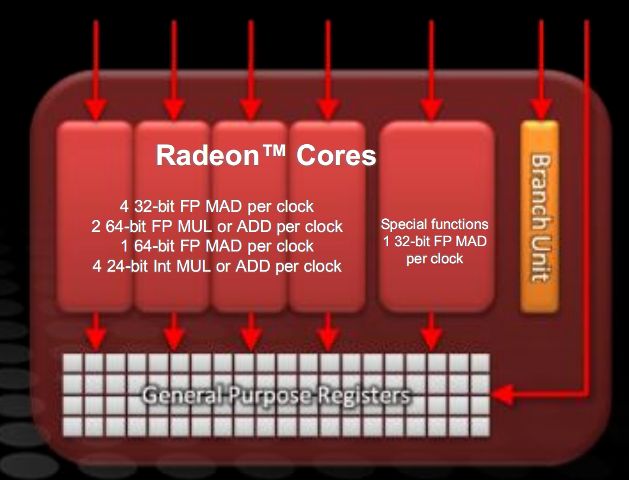
In particolare in figura possiamo notare la struttura dell’unità VLIW 5 delle architetture grafiche AMD. L’unità delle funzioni speciali può eseguire una moltiplicazione e addizione (MAD) in virgola mobile (FP) per ciclo, oppure un passo di elaborazione di una funzione speciale (come funzioni trascendenti, esponenziali eccetera) per ciclo.
Le restanti 4 unità di esecuzione possono eseguire 4 FP MAD a 32 bit, oppure una qualsiasi combinazione di 2 tra addizioni e moltiplicazioni FP a 64 bit, una FP MAD a 64 bit oppure una qualsiasi combinazione di 4 tra addizioni e moltiplicazioni intere a 24 bit.
Dal confronto con “Redwood”, si può vedere che mentre quest’ultimo ha un controller RAM a 128 bit per memorie DDR3 o GDDR5, UVD di seconda generazione e 4 controller per il display, capaci anche di un certo livello di supporto alla tecnologia Eyefinity, “Sumo” ha un collegamento diretto al controller RAM DDR3 a 128 bit presente sul North Bridge, UVD di terza generazione e 2 controller dedicati per il display. Se si rinuncia alla interfaccia PCI Express x16, è possibile configurare altre uscite video, per consentire l’implementazione della tecnologia EyeFinity.
L’integrazione on die della GPU e il collegamento diretto al North Bridge hanno giovato alla GPU, compensando in parte il fatto di avere un controller DDR3 condiviso con la CPU.
La GPU, infatti, è collegata al resto del sistema da ben 3 BUS.
Il primo è il collegamento “Garlic”, che è un collegamento diretto, senza controllo di coerenza, a bassa latenza, a 128 bit, tra GPU e controller RAM, arbitrato dal solo Front-End del controller RAM, che gli garantisce alta priorità e bassa latenza. La frequenza a cui opera tale collegamento dovrebbe essere presumibilmente quella del Northbridge, che dovrebbe essere intorno ai 2GHz, visto che AMD dichiara una banda superiore ai 30GB/s verso il controller RAM, che con 2 miliardi di trasferimenti al secondo si superano di poco. E’ un miglioramento rispetto ai 64 bit del BUS per la GPU di Ontario/Zacate.
Il secondo è il collegamento “Onion”, che interfaccia la GPU con il sistema coerente, composto dalla memoria, dalla CPU e le loro cache, che ubbidisce al protocollo MOESI. Questo collegamento diretto e a bassa latenza è un notevole passo avanti. Con una GPU esterna, in particolare con un IGP, si doveva passare per il bus di collegamento tra scheda grafica (o North Bridge nel caso di IGP) e CPU, attendere che il relativo North Bridge integrato controllasse le cache e eventualmente la RAM e rispedisse i risultati. Ora i due controlli possono essere fatti indipendentemente e in parallelo (attraverso entrambe le interfacce Onion e Garlic) e con una latenza molto più bassa.
Il terzo collegamento è quello diretto tra GPU e l’unità GIO, per l’accesso al controller PCI Express, per un eventuale CrossFire con schede discrete e per la gestione delle uscite video. La stessa sorte non tocca ai core della CPU che, per accedere al GIO, devono passare per il North Bridge e subirne le relative latenze e attese.
Un altro grande vantaggio di una GPU integrata nello stesso chip della CPU è relativo allo scambio di dati in memoria. Con le schede grafiche convenzionali, per effettuare il rendering di una scena, devono essere usate varie strutture dati: griglie di vertici (mesh), informazioni di colore e illuminazione e texture mapping, per la colorazione finale.
Queste informazioni sono create dal software 3D in memoria e sono passate al driver della scheda grafica. Poiché i processi lavorano con la memoria virtuale, è possibile che per accedervi il driver debba addirittura caricarli dal disco. In ogni caso devono essere trasferiti nella memoria interna della scheda video, tramite il bus PCI Express.
Analogamente succede per i calcoli GPGPU, dove, in più, i dati devono percorrere anche il tragitto inverso, per caricare in memoria principale i risultati del calcolo.
Tutto questo con una APU non è più necessario. L’APU Llano implementa 2 tecniche per velocizzare queste operazioni.
La prima si chiama Zero Copy e consente di non copiare più i dati, ma dire semplicemente alla GPU dove sono e poterli utilizzare direttamente. Ciò è possibile perché la GPU può accedere direttamente alla RAM. Ma la memoria virtuale consente di spostare i dati dentro e fuori dalla memoria e riallocarli a piacimento. Llano non implementa ancora un gestore della memoria virtuale sofisticato per consentire di sfruttare uno spazio di memoria unificato. Le successive architetture lo implementeranno e renderanno la GPU un vero e proprio coprocessore vettoriale, un po’ come le prime FPU apparse anni fa.
Per evitare problemi, entra in scena la seconda tecnologia: Pin in Place. Questa consiste nel bloccare le strutture dati in un’area specifica di memoria, affinché la GPU possa ritrovarle e accedervi in sicurezza e affinché non sia portata fuori memoria, sul disco rigido, allungandone i tempi di accesso.
In realtà la CPU usa la classica tecnica di memoria virtuale, chiamata demand paging, gestita dal SO, mentre la GPU ha la paginazione gestita dal driver video, di concerto ovviamente con il sistema operativo per implementare le due tecnologie di cui sopra. Il Pin in Place serve proprio a questo: il driver grafico blocca in memoria delle pagine per i suoi usi, tramite i normali meccanismi offerti dal sistema operativo, e poi mappa tali pagine nella memoria virtuale della GPU in modo che essa vi possa accedere.
La GPU gestisce la memoria con una logica più rilassata rispetto alle CPU x86, consentendo un riordinamento degli accessi più spinto, che portano migliori prestazioni. La GPU deve accedere alla memoria con le regole più restrittive della CPU solo quando accede alla memoria Pinned, per evitare di interferire con la CPU e la CPU invece si appoggia al driver per sincronizzarsi con al GPU.
Veniamo ora ai dettagli sull’interscambio di informazioni tra CPU e GPU.
La GPU accede alla memoria in modalità interleaved, ossia blocchi di dati consecutivi sono alternati nei canali RAM, per ottimizzare la banda di accesso, mentre la CPU accede alla memoria tipicamente in modalità non interlacciata o comunque in modalità ottimizzata per la latenza.
Gli accessi alla RAM da parte della CPU seguono il classico approccio coerente con il protocollo MOESI, per la RAM normale. La memoria riservata alla GPU viene vista come memoria non cacheabile e con write combining attivato. Scritture della CPU verso tale memoria seguono il classico protocollo per tali accessi e i dati transitano dal bus “Onion” verso la GPU, che poi li scrive in memoria, ottenendo in totale una velocità comunque superiore a quella ottenuta tramite il PCIExpress (si parla di circa 8GB/s). Letture della memoria GPU da parte della CPU sono piuttosto lente sia perché la memoria è uncacheable, e quindi tramite il bus “Onion” si deve forzare la scrittura di tutti i dati modificati dalla GPU in RAM, sia perché è possibile avere solo una di queste transazioni in atto in ogni istante.
La GPU accede alla memoria RAM riservata alla GPU in modalità non coerente, e perciò non affetta da tutto l’overhead che la coerenza si porta appresso, e in modalità interleaved sui canali di memoria. Tutto questo lo fa tramite il BUS “Garlic”, che ha alta priorità ed ha un collegamento diretto con il controller della memoria. Il driver comanda alla GPU di leggere la memoria non riservata ad essa, quando si devono prelevare dati esterni, come mesh, texture o dati per il GPGPU. Comanda scritture su tale memoria quando si devono passare i risultati di un calcolo GPGPU oppure per copiare il frame buffer in RAM per elaborazioni varie. La memoria non riservata alla GPU è gestita o in modalità uncached, o con il protocollo di coerenza MOESI, implementato dai core della CPU. Se la memoria è non cacheable, allora le cache non devono essere controllate, così non è necessario usare il bus “Onion” per accedere al dominio coerente. Si può usare il bus “Garlic”, ma la memoria deve essere bloccata (pinned), perché la GPU non implementa ancora in hardware la memoria virtuale in modalità compatibile con i core x86, in più essa in genere non è acceduta in modalità interleaved, perciò è un po’ più lenta. Ma non quanto l’accesso alla memoria cached, che richiede di passare per il bus “Onion”, essere accodato nella coda IFQ e richiede il controllo delle cache delle CPU. Anche qui la memoria deve essere bloccata, poiché la GPU lavora con indirizzi fisici.
Quando sarà implementata nelle GPU di future generazioni la memoria virtuale in modo identico a quello delle CPU x86, allora si potrà parlare di spazio di memoria unificato e tali accorgimenti software non saranno più necessari. Sarebbe persino possibile paginare su disco la memoria grafica, se implementassero lo scambio di segnali di page fault dalla GPU alle CPU.
Queste tecnologie possono, in casi eccezionali, far avere una velocità superiore a quella di una scheda video discreta. Ma la condivisione del controller RAM rende comunque la GPU integrata un po’ più lenta di una sua discreta equivalente.
La GPU, a differenza di quella implementata nel Sandy bridge, supporta pienamente le DirectX 11 e il filtraggio anisotropico indipendente dall’angolo.
Altre caratteristiche supportate sono l’OpenGL 4.1, l’OpenCL 1.1 e le tecniche di anti-aliasing MSAA, SSAA e MLAA.
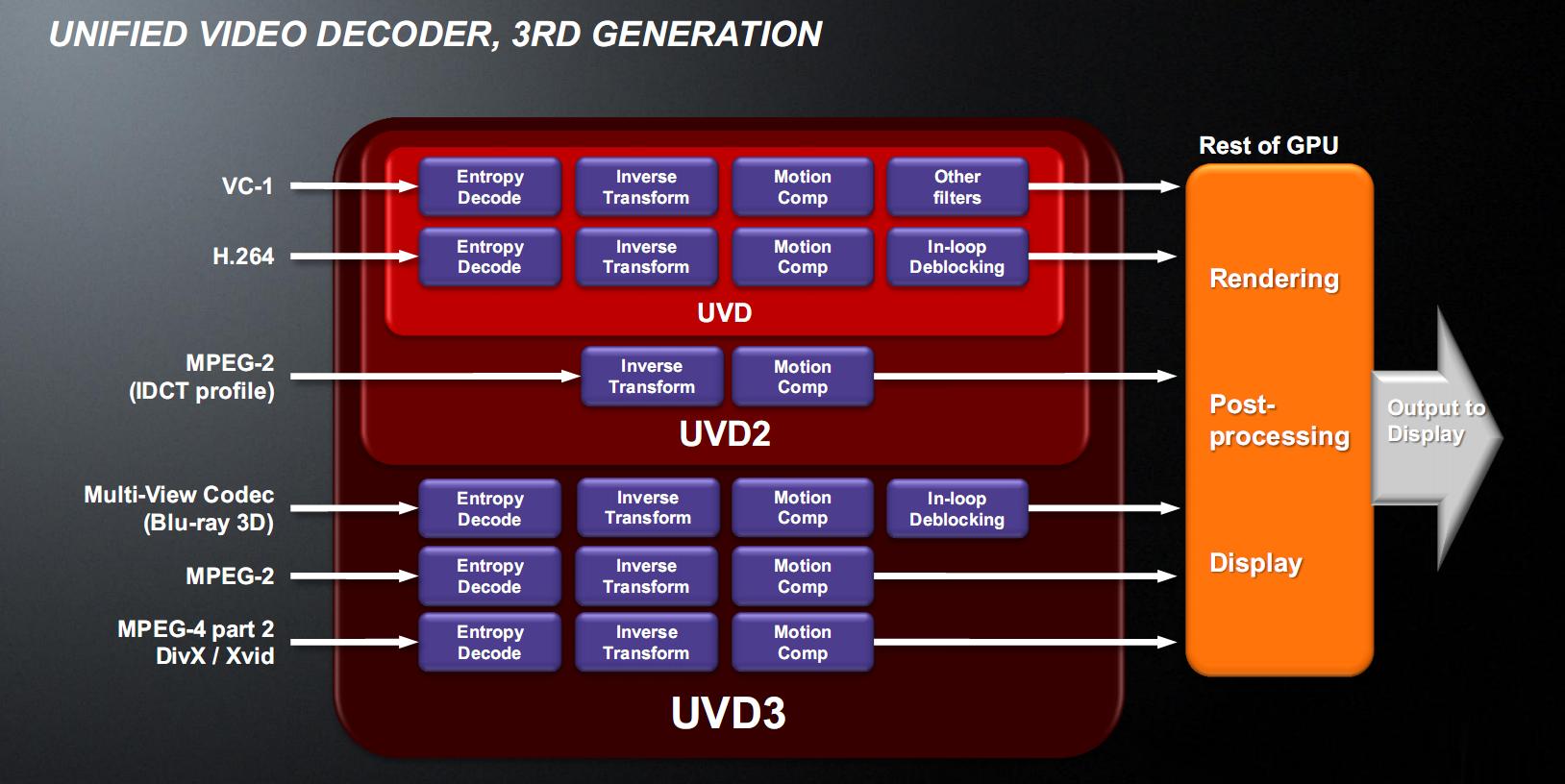
In figura è possibile vedere un diagramma a blocchi delle varie generazioni di UVD. La terza generazione, implementata in Llano, è in grado di accelerare in hardware i codec MPEG-4 Part 2 (di cui fanno parte anche i codec DivX e Xvid), MPEG-2, e il codec Multi-View (MVC) utilizzato per l’accelerazione dei contenuti Blu-ray 3D, che possono essere visualizzati tramite la porta HDMI 1.4a di cui Llano è dotata.
La decodifica è fatta tutta nel blocco UVD3, così il resto della GPU può essere messa in risparmio energetico avanzato (power gating) e risparmiare molta energia.
Dual Graphics
Ultimo capitolo per quanto riguarda la GPU di Llano è la tecnologia Dual Graphics. Essa consente di accoppiare, come la tecnologia CrossFire, schede video per incrementare le prestazioni. Ma a differenza di quest’ultima, consente di bilanciare il carico tra le GPU, tenendo conto delle differenze di potenza.
Il meccanismo non è perfetto, essendo dipendente molto dalla qualità e maturità dei driver e inoltre funziona al meglio con applicazioni DirectX 10 e 11. Con applicazioni DirectX 9, le prestazioni sono pari a quelle della scheda più lenta.
Come abbiamo visto in precedenza, le tecnologie CrossFire/DualGraphics ed EyeFinity sono mutualmente esclusive a meno di non accontentarsi di un numero inferiore di interfacce per i display: il controller PCI Express x16 è suddivisibile in due controller x8 di cui uno può essere utilizzato per il CrossFire e uno per i display aggiuntivi. Naturalmente per ottenere il massimo numero di interfacce video è necessario rinunciare al supporto CrossFire, così come per ottenere un supporto CrossFire pieno, con interfaccia x16 o con due interfacce x8 per effettuare un triplo CrossFire è necessario rinunciare al supporto EyeFinity.
Nel caso in cui la differenza di prestazione tra la scheda o le schede discrete abbinate alla GPU integrata siano notevoli, l’incremento di prestazioni rispetto solo uso della scheda discreta è modesto.
In compenso, però, AMD ha implementato i driver in modo da poter indirizzare le chiamate OpenCL 1.1 alla GPU integrata senza appesantire le GPU discrete, qualora queste stiano elaborando un carico 3D gravoso.
AMD Turbo Core 2.0 e AMD System Monitor
La tecnologia TurboCore evolve dalla sua prima implementazione nel Thuban. In tale architettura l’incremento di clock era effettuato solo in ben specifiche condizioni, ossia quando il 50% dei core era in idle, e solo con una logica di tipo on/off, indipendentemente dal margine di TDP.
Questo perché la prima implementazione del TurboCore era molto conservativa, in quanto non verificava in tempo reale il consumo effettivo. Quindi le condizioni di intervento e il margine di incremento di clock dovevano essere tenuti molto conservativi per evitare di sforare il TDP anche nel caso peggiore.
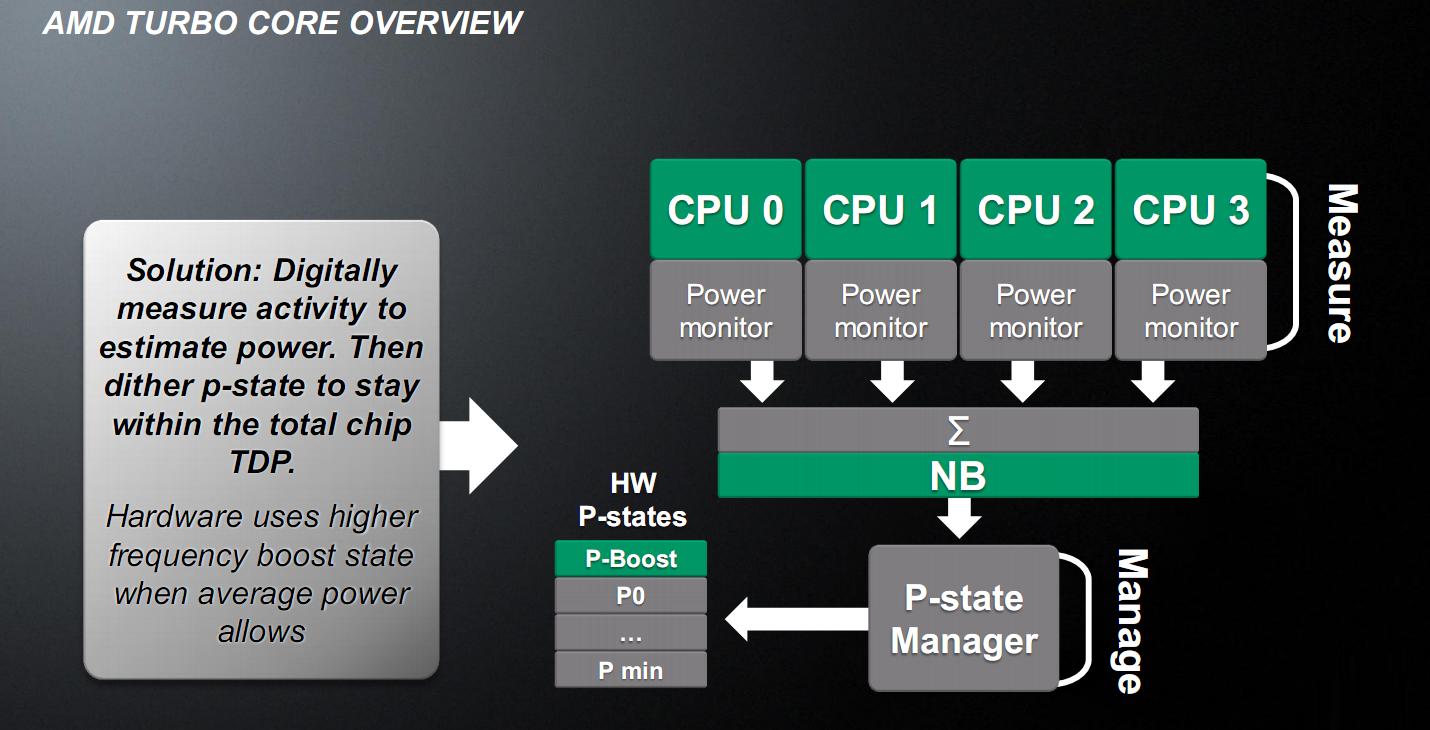
Tutto questo cambia con il TurboCore, versione 2.0. Innanzitutto è stata introdotta una unità detta APM (Advanced Power Management), che misura digitalmente 95 segnali per ogni core, più altri sparsi per tutto il chip, per stimare, con una precisione superiore al 98% (ossia con meno del 2% di margine di errore) la potenza dissipata in un intervallo di un centesimo di secondo, o 10 ms.
Confrontando questa situazione con quella del Thuban, dove l’intervento di overclock era effettuato in modalità cosiddetta a catena aperta, ossia dove non si misura a posteriori l’effetto dell’incremento di clock sul TDP e quindi si deve essere molto conservativi, la modalità di intervento del TurboCore 2.0 può essere classificata come a catena chiusa (con feed-back), poiché si misura il TDP effettivo e si è in grado di attuare una regolazione.
L’APM misura una stima del TDP non tenendo conto della temperatura e in modalità completamente digitale: in sostanza misura la percentuale di attività delle varie unità, ricavando il consumo totale, conoscendo quello massimo di ogni unità.
Messo a confronto con il metodo di misura della controparte Intel, analogico e fortemente dipendente dalla temperatura, abbiamo un andamento del clock molto riproducibile per Llano, anche se potenzialmente non ottimale in quanto il TDP massimo potrebbe non essere raggiunto, a causa dei margini di sicurezza, comunque presenti, per l’intervento dell’overclock.
Un’altra novità del TurboCore è la modalità di incremento del clock. Mentre nel Thuban era del tipo on/off, in Llano è usato un algoritmo di dithering, che consiste nel calcolare la percentuale di tempo, di un intervallo prefissato, in cui la CPU deve stare nello stato a clock più alto, in modo che la potenza media durante l’intervallo sia più alta possibile, rimanendo al di sotto del TDP. Questo implica anche che la frequenza "efficace" della CPU sia un valore intermedio tra quella di default e quella di Turbo. Ossia che la CPU si comporti come se avesse quella frequenza intermedia. Facciamo un esempio con le frequenze del Thuban top di gamma. La frequenza base è di 3.3GHz e la frequenza di turbo è 3.7GHz. Supponiamo che il TDP massimo sia 100W come per Llano. Supponiamo, infine, di avere un carico di lavoro che a 3.3GHz fa assorbire alla CPU 90W, ma a 3.7GHz 102W. Se noi implementassimo l'innalzamento del clock come nel Thuban, anche avendo l'APM, noi non potremmo aumentare il clock, perchè sappiamo che potremmo sforare il TDP. Quest'algoritmo calcola la percentuale di tempo ottimale a cui la CPU deve stare nello stato di clock alto. Supponiamo che il calcolo dica che con il 90% di tempo nello stato di turbo, il TDP sia di 99W. Giusto sotto il limite. Abbiamo che la frequenza effettiva della CPU è 3.3*0.1+3.7*0.9=3.66GHz. Questo è un grande vantaggio rispetto all'architettura Thuban e anche alle architetture Intel: in tal caso, infatti, il numero di stati di turbo è limitato e si va a passi di 100 o 133MHz. Con il meccanismo AMD, invece, si può virtualmente avere tutta la gamma di frequenze efficaci comprese tra quella base, in cui è garantito il non superamento del TDP, e quella di clock massimo.
Questo consente di sfruttare al massimo le capacità dissipative del sistema e consente di selezionare una frequenza di Turbo più elevata: infatti nel Thuban si era limitati dal fatto che la CPU poteva cambiare velocità di clock con una certa velocità senza poter modulare, con un algoritmo di dithering, il tempo di permanenza nello stato a clock alto.
Come per il Thuban, il P-state a clock più alto è uno stato hardware invisibile al sistema operativo, che rileva sempre che la CPU sia allo stato di velocità massimo, ma alla frequenza di default.
Questo causa problemi nella rivelazione della frequenza effettiva della CPU ed infatti sono stati introdotti dei registri interni (della famiglia dei cosiddetti MSR, Model Specific Registers, leggibili con l’istruzione CPUID), che consentono di calcolare una frequenza media effettiva del core, poiché essi contano automaticamente il numero di colpi di clock visti dalla CPU in un dato intervallo.
In Llano solo la CPU può incrementare il proprio clock, anche se AMD si è riservata la possibilità di poter incrementare anche il clock della GPU in modelli futuri (e sembrerebbe che già il successore di Llano, Trinity, basato su architettura Bulldozer dal lato CPU, possa implementarlo).
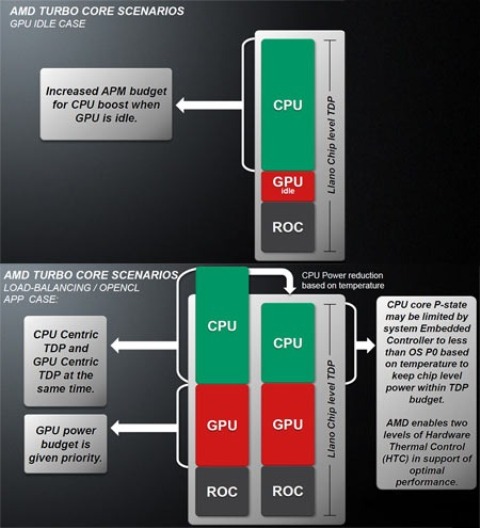
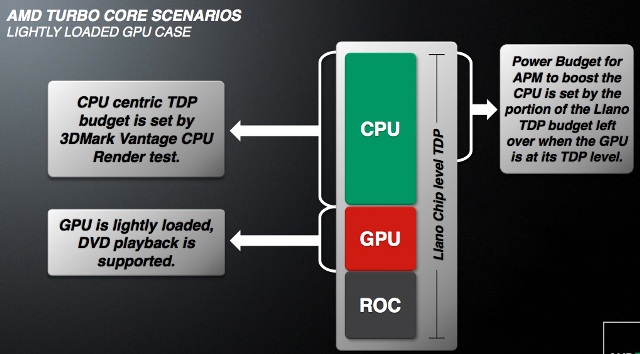
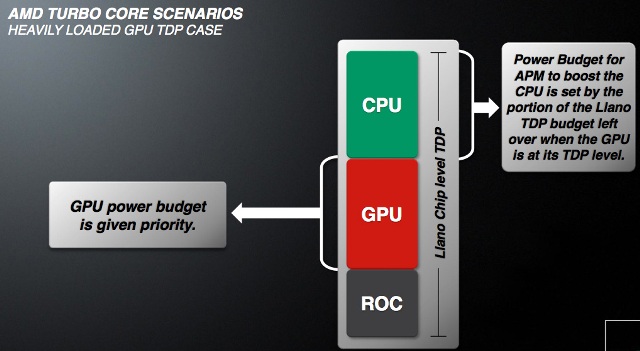
Nelle figure possiamo vedere il comportamento del TurboCore in alcuni scenari tipici. La GPU può solo vedere il suo clock ridotto o essere spenta del tutto, ma in ogni caso ha la precedenza: il P-state della GPU dipende solo dal carico richiesto ad essa ed è la CPU che vede l’intervento del Turbo limitato dal TDP totale del chip, GPU compresa.
Fino ad ora abbiamo visto che la temperatura del chip non è entrata effettivamente nell’equazione del turbo. Ma c’è un meccanismo di protezione che abbassa il clock delle CPU al di sotto del valore di default, qualora la temperatura superi dei valori critici.
A parte il malfunzionamento del sistema di dissipazione, l’unico modo per cui questo possa succedere è in scenari di calcolo intensivo, in cui sia CPU che GPU sono impegnati al massimo. Questi possono essere programmi di stress test appositamente sviluppati o anche programmi OpenCL che impegnano al massimo la CPU e la GPU.
AMD System Monitor
AMD ha sviluppato un software di monitoraggio particolarmente indirizzato alle nuove APU Bobcat e Llano, che funziona anche con le vecchie piattaforme, rilevando e monitorando i componenti AMD (CPU, GPU, APU e IGP) presenti nel sistema.
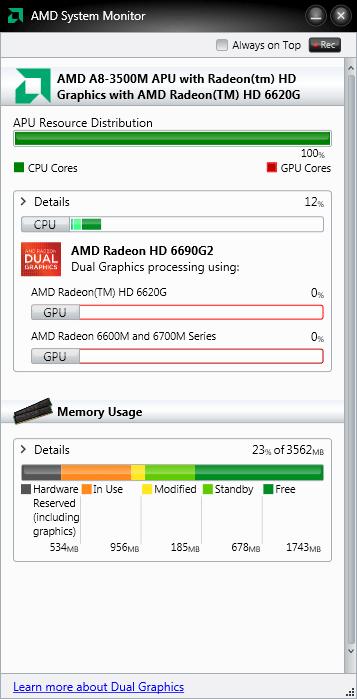
L’applicazione ha due livelli di dettaglio, selezionabili indipendentemente per la parte relativa agli elementi elaborativi (CPU, GPU, IGP e APU) e per la parte relativa alla memoria, tramite il pulsante contrassegnato dalla scritta Details.
Al livello di dettaglio inferiore, nella sezione relativa alla CPU, l’applicazione mostra l’utilizzo in percentuale dei diversi core. Se è presente una APU è anche mostrata la suddivisione delle risorse tra core e GPU.
Nella sezione GPU è visualizzata la percentuale di utilizzazione di tutte le GPU AMD istallate (incluse le schede discrete, IGP e la parte grafica delle APU, di fabbricazione AMD).
Nella sezione memoria è visualizzata la distribuzione della memoria tra i vari tipi presenti nel sistema (riservata in hardware, in uso, modificata, in stand by) e la memoria libera, espressa come percentuale della memoria totale.
Al livello di dettaglio superiore, nella sezione relativa alla CPU, sono mostrate informazioni aggiuntive dettagliate per ogni core, comprese le frequenze operative approssimate.
Nella sezione GPU sono visualizzate, oltre alle informazioni di base, le frequenze di GPU e memoria video e la velocità corrente della ventola GPU (se presente).
Nella sezione memoria sono visualizzati, oltre alle informazioni di base, ulteriori dettagli del sistema, tra cui la frequenza della memoria RAM principale.
Conclusioni e prospettive future
L’architettura Llano è molto di più che una fusione di una CPU di classe Propus e una GPU di classe Redwood.
Sono state implementate svariate tecniche di risparmio energetico e una infrastruttura hardware e software capace di sfruttare le sinergie possibili quando due componenti sono integrati nello stesso chip.
Il rapporto prestazioni/consumo a livello di piattaforma è incrementato sia rispetto alle precedenti piattaforme AMD, sia rispetto alla piattaforma concorrente, soprattutto considerando le applicazioni che si avvalgono della accelerazione della GPU.
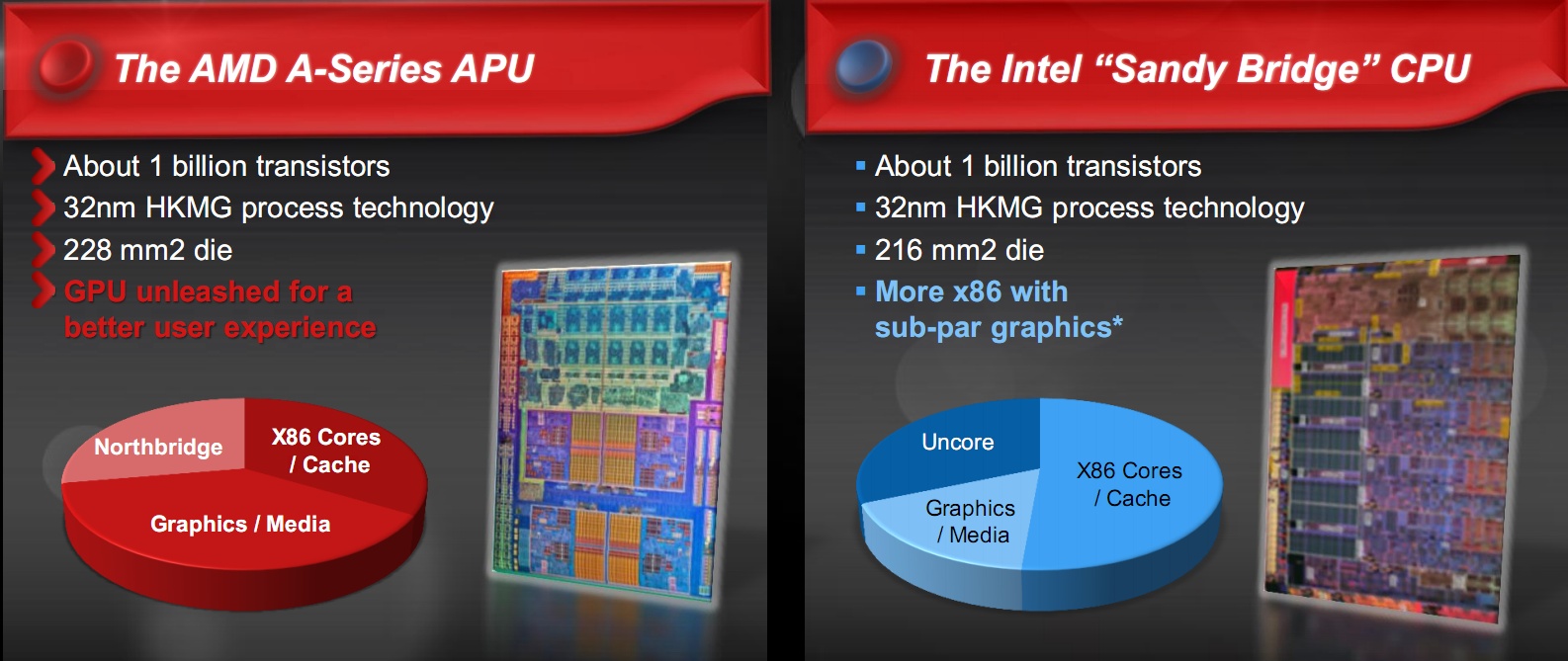
Il compromesso sull’occupazione del chip è a favore della parte grafica nella architettura AMD, dove quest’ultima può vantare maggiore esperienza e know-how derivata dall’acquisizione di ATI.
D'altronde il trend futuro, grazie anche alla promozione del GPGPU, è di sempre un maggiore uso del processore grafico anche per compiti non strettamente ludici.
Il motivo principale è la grande capacità di calcolo delle GPU, unita a un consumo tutto sommato accettabile, che rende il rapporto prestazioni/consumo particolarmente favorevole.
Ciò non significa che le CPU saranno abbandonate, poiché esistono compiti in cui esse sono più efficienti delle GPU.
Una integrazione spinta tra questi due elementi è auspicabile e il futuro va in questa direzione: l’architettura Bulldozer sgancia in modo più marcato la FPU dal resto del core, preparando il terreno per un possibile futuro uso delle unità GPU come coprocessore matematico.
Il tassello mancante è l’unificazione dello spazio di indirizzamento tra CPU e GPU, che in Llano è implementato a livello di driver, ma che con le successive architetture dovrebbe essere implementato ad un livello ancora più basso.
Una volta implementate tali funzionalità, il termine Fusion coglierà in pieno l’essenza della strategia AMD.
Marco Comerci
Test sulle CPU effettuati da Angelo Ciardiello